

You want to work from home, but every remote listing feels like a trap. One promises $10 per hour for AI training work from your couch. Another offers $15 for what looks identical. A third wants $45 for "certification materials" before you can apply.
Here's what most job guides won't tell you: the vast majority of platforms advertising remote data annotation work can't actually deliver quality work remotely. They end up paying poverty wages because they compete on price, not quality — and remote work without measurement technology produces garbage.
Platforms like DataAnnotation that succeed remotely aren't just allowing flexibility as a perk. They built sophisticated technology that measures quality in real-time across thousands of workers in different time zones.
This infrastructure costs money to build, but enables premium pricing because it proves value to AI companies training frontier models. Understanding this distinction determines whether you access legitimate $20-$50+ per hour work or waste months on commodity microtasks.
This guide shows you why remote AI training is fundamentally different from office-based annotation work, what capabilities remote platforms actually test, and why remote work at technology companies positions you at the infrastructure layer of global AGI development rather than the gig economy.
1. Understand why remote AI training requires technology (not just trust workers)
Most people assume remote work is just "same job, different location." For simple tasks like customer service or data entry, that's true. For AI training work that shapes how frontier models reason, understand language, and make decisions, remote work requires infrastructure that most platforms simply don't have.
Why proximity-based quality control fails remotely
Consider what in-person annotation looked like historically.
A manager walks around an office, checking workers' screens, answering questions in real time, and catching errors through observation. Quality control happens through proximity — you can see when someone's rushing through tasks, when they're confused, when they need help.
This is why AI training at commodity platforms proliferated: they aggregate workers in physical locations, verify credentials at hiring, then rely on supervision to maintain standards.
Remote work breaks this model entirely. You can't walk around checking screens. You can't answer questions in real-time. You can't observe work patterns to identify who's struggling.
Without systematic quality measurement, remote annotation produces inconsistent results because there's no feedback mechanism linking worker performance to platform standards.
This is why most platforms pay peanuts at $5 to $10 per hour. They verify your credentials, give you access, hope for the best, and compete on price because they can't prove their data is better than cheaper alternatives.
The infrastructure gap between $5/hour and $20/hour remote work
Platforms that successfully operate remote work at $20 to $50+ per hour have built measurement technology that's actually superior to in-person supervision. Real-time quality detection across thousands of workers identifies patterns no human manager could spot.
DataAnnotation exemplifies the technology-first approach. Our tier structure ($20+ for general work, $40+ for coding and STEM, $50+ for professional credentials) isn't arbitrary remote work pricing.
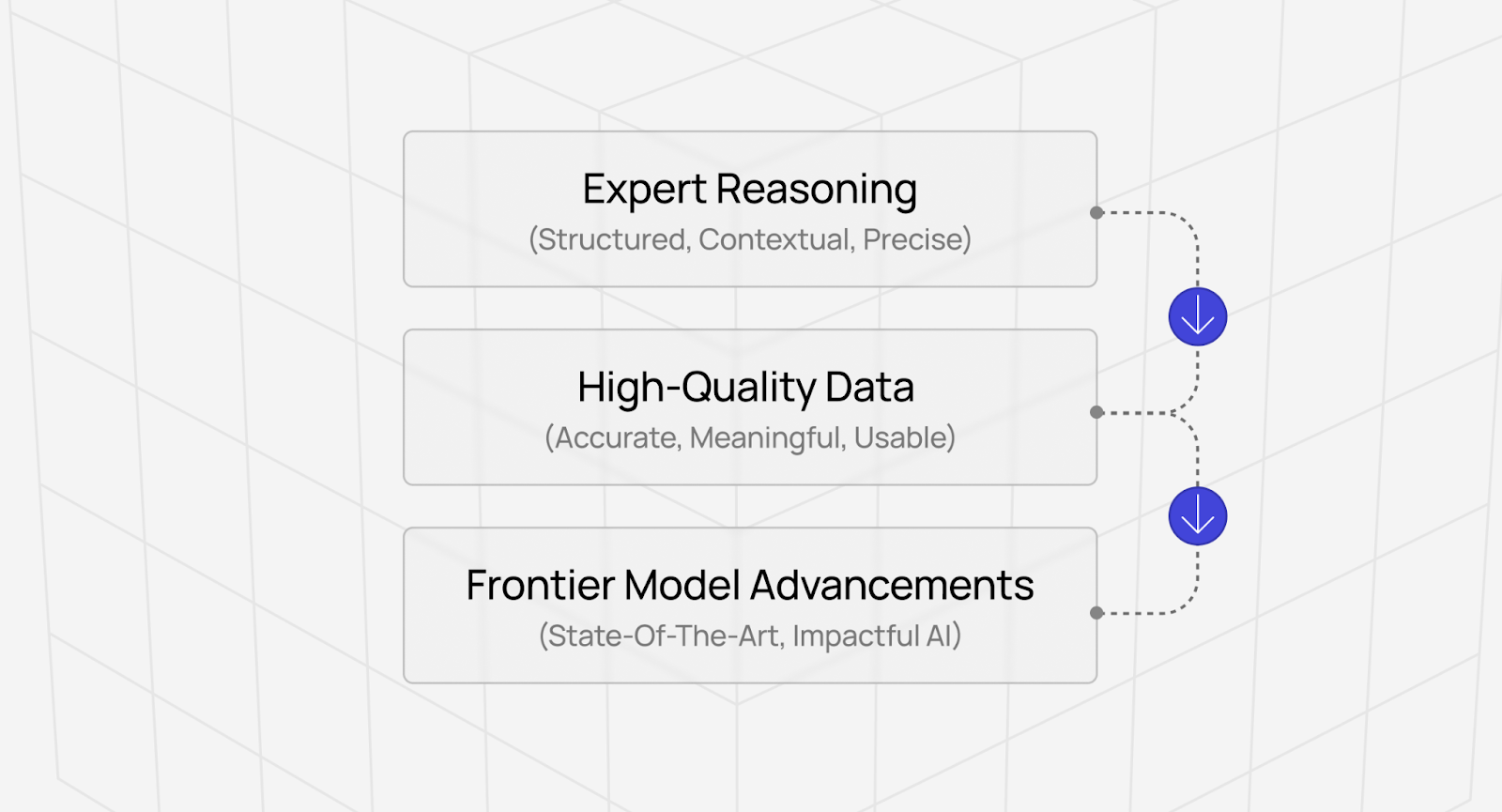
It reflects sophisticated measurement systems that identify genuine expertise rather than pattern-matching from examples, enabling premium rates because the technology proves ROI to customers and trains models like Claude, GPT, and Gemini.
The practical implication: when selecting platforms, if onboarding focuses purely on credential verification without capability demonstration, they're hoping your resume predicts performance rather than measuring actual output. This works poorly for in-person annotation and fails in remote work where supervision isn't available.
2. Build self-direction capabilities that remote work actually tests
Remote AI training platforms don't just test your knowledge — they test whether you can maintain quality standards without someone checking your work every hour. This distinction separates workers who thrive remotely from those who need supervision to stay focused.
What disappears when you remove real-time supervision
Think about what changes when work moves remote.
In an office, you can tap a colleague's shoulder when you encounter an ambiguous case, raise your hand for a manager when guidelines don't cover a situation, and see how others are approaching similar problems.
Remote work eliminates these crutches.
You make judgment calls independently, apply principles to novel situations without real-time guidance, and maintain consistent standards across all projects without feedback until quality reviews are complete.
These aren't barriers to remote work — they're filters for the capabilities frontier model training now requires.
Frontier AI systems now need annotators who understand the principles deeply enough to extrapolate to new situations, who maintain systematic reasoning rather than case-by-case intuition, and who can identify when they need to spend 30 minutes on a single evaluation versus 5 minutes.
In-person supervision can paper over a shallow understanding through constant guidance. Remote work can't, which means remote platforms must assess these capabilities directly.
The capabilities frontier platforms measure
The specific skills that remote environments test differently include:
- Native-level writing precision that identifies when AI responses drift in tone without someone pointing it out
- Critical reasoning that evaluates logical chains without peer discussion
- Systematic attention that maintains consistency across datasets without manager spot-checks
- Principled judgment that applies guidelines to cases they don't explicitly cover without real-time clarification
Building these capabilities requires deliberate practice on ambiguous cases without immediately seeking external validation. When you encounter something that guidelines don't cover, resist the urge to Google the "right answer."
Instead, articulate what principles the guidelines establish, how those principles might apply to this novel case, and what considerations make the judgment difficult. This develops the self-directed reasoning that remote platforms need, as their measurement systems can identify quality but can't provide real-time guidance for every task.
For workers transitioning from office-based or gig work, this represents the steepest learning curve. You're not just learning what good annotation looks like — you're learning to maintain those standards independently across hundreds of hours of work.
But this barrier creates the value proposition: workers who develop genuine self-direction capabilities become more valuable over time as they require less oversight, catch more edge cases without prompting, and maintain consistency that compounds across large projects.
3. Choose platforms where technology enables remote quality measurement
The economic reality of remote annotation work: platforms that lack measurement technology compete on price and pay poverty wages. Platforms with sophisticated measurement infrastructure can prove value to customers and justify premium pricing.
Understanding this distinction prevents wasting months on platforms that advertise remote work but can't actually support quality at scale. The telltale signs appear during onboarding and in how platforms describe their operations.
Why measurement infrastructure determines remote pricing economics
Commodity platforms attempting remote work focus heavily on credential verification — educational background, years of experience, and previous employment. This makes sense for in-person environments where supervision compensates for hiring mistakes.
However, it fails remotely because credentials predict performance weakly, and remote environments can't course-correct through observation.
These platforms typically pay flat rates ($5 to $15 per hour) because they can't differentiate worker quality, hoping that volume and low prices overcome their inability to prove that data improves model performance.
Technology companies like DataAnnotation, operating at the frontier of remote work, explicitly explain their measurement infrastructure. They describe performance-based tier advancement and how they verify that workers contribute value.
DataAnnotation's tiered compensation isn't just different pay for different credentials — it reflects continuous measurement that identifies when workers demonstrate expertise through their output rather than their resume.
Consider what measurement technology actually enables.
When a platform can track that certain workers catch edge cases others miss, or identify errors automated validators don't detect, they can price these workers at $40 to $50+ per hour because they can prove to AI companies that this feedback reduces the cost of expensive training failures.
Without measurement systems, platforms can't distinguish these high-performers from median workers, forcing everyone into the same low-pay bracket regardless of capability.
How global talent access raises quality ceilings rather than lowering them
The global talent pool advantage amplifies this dynamic. Remote work removes geographic constraints on hiring — you're not limited to those who live near an office.
At DataAnnotation, our work runs globally with workers spanning continents and time zones, accessing expertise that couldn't be concentrated in any single physical location.
This creates an interesting paradox: remote work actually raises the quality ceiling rather than lowering it, because platforms can connect the Stanford professor working from California, the computational physicist in Berlin, and the practicing attorney in Singapore, and coordinate their expertise through technology rather than requiring proximity.
Before applying to remote platforms, verify they have an actual quality measurement infrastructure through specific questions:
- How do they assess work quality beyond initial credential checks?
- How do tier advancements work — is it time-based or performance-based?
- Can they explain how they prove value to customers?
Legitimate answers involve technology and measurement. Vague answers about "experienced team review" or "industry standard practices" signal commodity-gig approaches that struggle to work remotely.
Verifying legitimate measurement systems before applying
Beyond measurement capability, verify basic legitimacy through review aggregation: Indeed and Glassdoor ratings from current workers, payment complaints on r/WorkOnline or Trustpilot, and Better Business Bureau history.
Universal scam flags still apply: upfront fees, pay below minimum wage, missing terms pages, and pressure to start without assessment. But for remote work specifically, the more complex problem is distinguishing legitimate platforms that can't support quality remotely from those with infrastructure that makes remote work actually viable at professional rates.
4. Pass assessments simulating actual working conditions
Remote assessment design reveals what platforms actually value. Platforms optimized for in-person work test whether you can follow instructions with guidance available. Platforms optimized for remote work test whether you can make sound judgments in isolation.
What assessment design reveals about remote work infrastructure
At DataAnnotation, our Starter Assessments deliberately simulate remote working conditions:
- You complete them independently without real-time support
- They require judgment on cases that guidelines don't explicitly cover
- They evaluate reasoning transparency through how you articulate decisions
- They measure time allocation judgment by seeing whether you identify when cases need deeper analysis versus quick resolution
Our assessment structure varies by expertise track, each testing capabilities relevant to that compensation tier:
- General assessments evaluate writing clarity, critical thinking, and attention to detail for $20+ per hour of work
- Language-specific assessments evaluate fluency for multilingual projects at $20+ per hour
- Coding assessments test programming knowledge across languages for $40+ projects
- STEM assessments in math, chemistry, biology, or physics measure domain expertise for $40+ work
- Professional assessments in law, finance, or medicine test specialized knowledge for $50+ opportunities
Most assessments require 60 to 90 minutes to complete thoughtfully, with specialized tracks potentially taking 2 hours due to complexity. This duration isn't arbitrary — it tests whether you can maintain focus and quality during the sustained work periods that actual projects require.
Why process transparency matters more than answer accuracy
The critical distinction from academic testing: remote assessments measure judgment process, not knowledge recall. When you encounter a case the rubric doesn't explicitly cover, platforms want to see how you think through applying principles rather than whether you guess the "right answer."
Many candidates fail by optimizing for speed rather than thoughtfulness, treating ambiguous cases as problems to avoid rather than opportunities to demonstrate reasoning, or trying to match imagined "correct answers" rather than showing systematic thinking.
Remote platforms need workers who recognize when cases require thirty minutes of careful analysis because catching a critical edge case matters more than completing high volume.
In-person supervision can course-correct workers who optimize for the wrong metrics. Remote measurement systems can only evaluate the output you produce, making initial judgment calibration essential.
Leveraging timezone independence for optimal assessment performance
The geographic advantage of remote work means you can take these assessments during your optimal focus hours, regardless of the platform's time zone. If you focus best at 6 AM, schedule your assessment then.
If you think most clearly at 11 PM, use that slot. Remote platforms measure output quality, not when you produce it, creating flexibility that office-based assessment centers can't match.
5. Scale through expertise depth, not work volume
Most workers assume "more hours worked = more income earned." This holds for commodity labor priced by time. Premium AI training follows different economics: as models get more sophisticated, the work becomes more complex rather than being automated.
Why automation risk decreases as model sophistication increases
At DataAnnotation, the quality ceiling keeps rising because we believe quality data is the bottleneck to AGI.
Consider the trajectory. In 2020, labeling sentiment as positive/negative/neutral had a low-quality ceiling (anyone could do it) and a high automation risk (models now handle this).
By 2023, evaluating RLHF preference pairs required judgment about which response better demonstrated helpfulness or honesty, creating a medium-quality ceiling with medium automation risk.
In 2025, debugging frontier model reasoning chains requires identifying where logic breaks down in multi-step proofs, creating an unlimited quality ceiling with low automation risk because this work trains the automation itself.
What tier structures reveal about measurement economics
The pattern matters: as AI capabilities advance, the work shifts from tasks models can automate to tasks that train models toward capabilities they haven't yet achieved. This means expertise becomes more valuable over time, not less.
Our tier structure reflects this reality:
Workers earning $20+ per hour demonstrate good writing, critical thinking, and attention to detail — thousands of workers can do this competently, so value comes from consistency and reliability.
Workers earning $40+ for coding or STEM work provide domain expertise that evaluates algorithmic elegance (not just syntax correctness), assesses scientific reasoning quality (not just fact accuracy), or identifies edge cases requiring specialized knowledge — hundreds of workers can do this competently.
Workers earning $50+ for professional work apply regulatory context, ethical standards, and domain-specific quality criteria from law, finance, or medicine — dozens of workers can do so at the level of frontier model training.
The compensation jump isn't arbitrary. It reflects measurement reality: we can verify general quality through automated validators and statistical patterns, but expert-level quality requires expensive human verification.
Identifying where your existing knowledge creates quality advantages
Rather than trying to "learn new fields" to access higher tiers, identify where your existing knowledge creates quality advantages.
If you have a coding background, your edge is recognizing when AI-generated code works but creates technical debt, or when solutions follow best practices rather than merely passing tests — you already developed this taste through years of debugging and code review.
If you have a STEM background, your edge is assessing whether reasoning chains support their conclusions or identifying methodological bias—your education taught you how experts evaluate quality.
If you have a professional background, your edge lies in applying contextual judgment in ambiguous situations — your career has taught you to navigate complexity.
Preparation for specialized assessments means refreshing fundamentals, not building entirely new expertise. For coding specialization, review common algorithmic patterns and language-specific best practices while focusing on evaluating code quality rather than writing code.
For the STEM specialization, review fundamental principles and common misconceptions, focusing on evaluating reasoning quality rather than fact accuracy. For professional specialization, review current regulatory standards, focusing on contextual appropriateness rather than technical correctness.
The goal is to demonstrate that your existing expertise enables quality judgments that general workers can't make and automated systems can't verify. As models get more capable, this work becomes more valuable because the gap between "passing automated checks" and "actually advancing model capabilities" widens.
Explore premium AI training jobs at DataAnnotation
Most platforms position AI training as gig work where you earn side income by clicking through microtasks. At DataAnnotation, we‘re at the forefront of AGI development, where your judgment determines whether billion-dollar training runs advance capabilities or optimize for the wrong objectives.
The difference matters. When you evaluate AI responses for technology platforms, your preference judgments influence how models balance helpfulness against truthfulness, how they handle ambiguous requests, and whether they develop reasoning capabilities that generalize or just memorize patterns.
This work shapes systems that millions of people will interact with.
Getting from interested to earning takes five straightforward steps:
- Visit the DataAnnotation application page and click “Apply”
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking and attention to detail
- Check your inbox for the approval decision (which should arrive within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. Just remember: you can only take the Starter Assessment once, so prepare thoroughly before starting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI — and you have the expertise to contribute.




