

In this article
Every major AI lab now promises transparency. They publish model cards, release benchmark scores, and document known limitations. The outputs look rigorous.
The reality is different. We've worked with systems where the published methodology and actual training pipeline diverged significantly. The model card listed biases they tested for, not biases they found. The "explainability tools" generated plausible narratives that had little relationship to actual model behavior.
True transparency conflicts with competitive advantage, clashes with regulatory uncertainty, and exposes a practical reality: most teams don't fully understand what their models learned.
What is AI transparency?
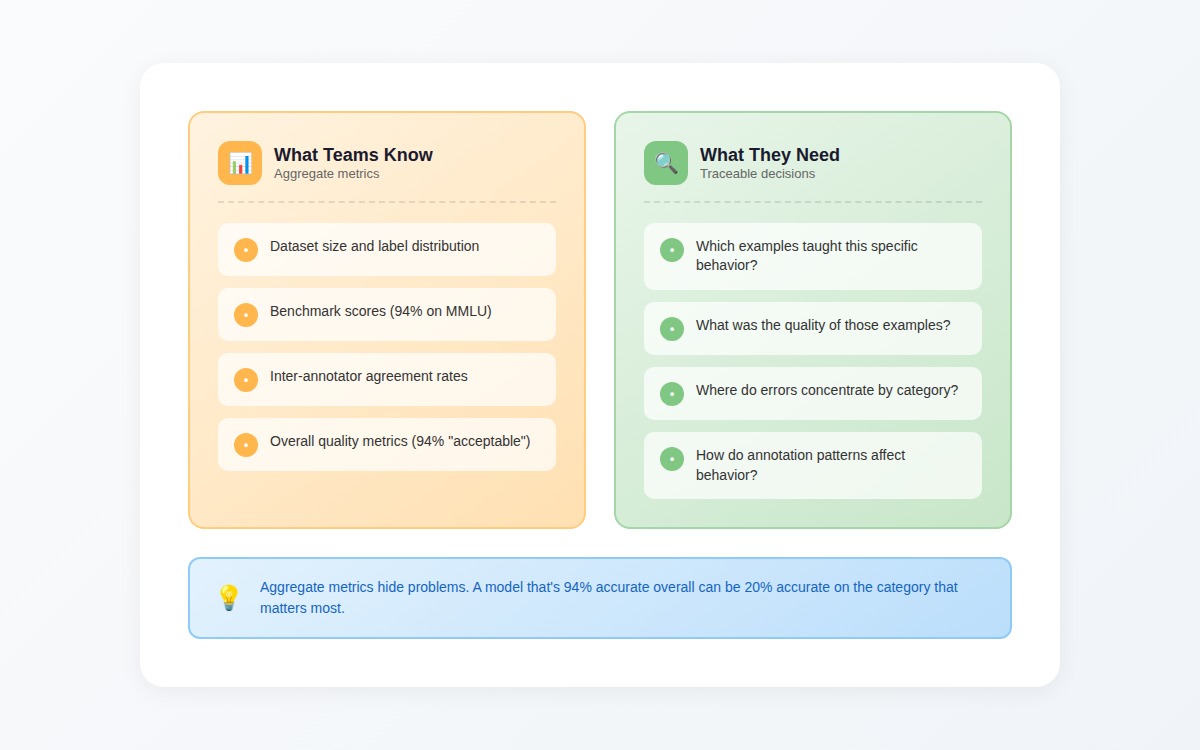
AI transparency is the ability to trace model behavior back to the training decisions that caused it. When a model fails, transparency means you can answer:
- Which training examples taught it this pattern?
- What was the quality of those examples?
- How do we fix it?
Most "transparency" efforts focus on explainability — post-hoc justifications for why a model made a specific prediction. That's useful, but it's not what breaks production systems. The transparency that actually matters is the connection between training data and model behavior. Without it, you're describing symptoms, not causes.
Beyond ethics, why is AI transparency important?
The case for AI transparency isn't just about ethics, but about operational necessity as well.
Debugging becomes possible. When a content moderation model flags breast cancer support groups as adult content, transparency means you can trace that decision to training examples that overrepresented certain medical phrasings. Without it, teams spend weeks debugging model architecture when the problem is training data.
Improvement becomes systematic. If you can't connect model failures to specific training patterns, every fix is a guess. You add more data, retrain, and hope. Transparency lets you identify exactly which examples taught the problematic behavior and replace them with better ones.
Compliance becomes achievable. Regulators increasingly require explanations for AI decisions. If you can't trace how your model learned a particular behavior, you can't explain it to auditors, customers, or courts.
Trust becomes earned. Users and stakeholders don't trust AI systems because companies say "trust us." They trust systems they can verify. Transparency means showing your work; not just publishing a model card, but demonstrating the connection between training decisions and model behavior.
What are the current AI transparency regulations and standards?
Here's what matters now.
EU AI Act
The EU AI Act establishes the world's first comprehensive legal framework for AI transparency. Key provisions:
- High-risk AI systems must be designed for sufficient transparency so deployers can interpret outputs and use them appropriately. This includes documentation of capabilities, limitations, accuracy metrics, and any circumstances that may impact performance.
- General-purpose AI models (like GPT-4 or Claude) must comply with transparency requirements including technical documentation, training data summaries, and information sharing with downstream deployers.
- Generative AI systems must mark AI-generated content in machine-readable formats, disclose when users are interacting with AI rather than humans, and label deepfakes clearly.
NIST AI Risk Management Framework
The NIST AI RMF has become a de facto standard in the United States. While voluntary, it's increasingly referenced by state regulations and federal guidance.
The framework emphasizes four functions: Govern, Map, Measure, and Manage. Transparency appears throughout, particularly in requirements for documentation practices, accountability structures, and systematic monitoring of AI system behavior.
The 2024 Generative AI Profile added specific guidance for transparency in generative systems, including training data provenance and misuse risk reporting.
State-level regulations
California's SB-942 AI Transparency Act requires businesses to disclose when consumers interact with generative AI and clearly label AI-generated content.
Colorado's AI Act requires impact assessments, prohibits algorithmic discrimination, and mandates consumer disclosures when AI makes consequential decisions. It explicitly references NIST AI RMF compliance as a factor in enforcement.
What this means in practice
Regulatory transparency requirements focus on disclosure: telling users when they're interacting with AI, labeling synthetic content, documenting model capabilities. That's necessary but insufficient.
Operational transparency — the ability to trace model behavior back to training decisions — isn't yet mandated. But it's the foundation that makes regulatory compliance possible. If you can't explain why your model behaves a certain way, you can't comply with requirements to document its capabilities and limitations.
Where transparency fails: what we’ve seen
The benchmark problem
I’ve seen a content moderation model score 94% on standard safety benchmarks. Comprehensive evaluation suite, thousands of test cases, industry-standard metrics. It shipped to production handling 50,000 posts daily.
Within two weeks, it flagged breast cancer support groups as adult content and missed obvious hate speech variants.

The benchmark scores hadn't changed. The model performed exactly as trained. The problem: nobody could trace decisions back to training data patterns. The training set overrepresented certain medical phrasings and underrepresented linguistic patterns hate groups developed to evade detection.
Without transparency into training data lineage, the team spent nine days debugging the wrong layer of the stack.
The visibility problem
Here's what training pipelines look like at most organizations. The data gets collected from multiple sources, labeled by internal teams and external providers, undergoes quality checks, gets preprocessed and fed into training.
Each step generates metadata but none of it connects. When the model fails, you can't query which examples caused the behavior.
We worked with a team whose object detection model kept misidentifying wheelchairs. High-level metrics looked fine. When we traced it back, a specific batch job two months earlier had mislabeled 80% of wheelchair training images.
Aggregate label quality was still 94%, well within accepted range. But concentrated error in this category broke a critical use case. Without visibility into which examples taught the model about wheelchairs, they spent three weeks debugging architecture instead of data.
That visibility depends on training data created by people who document their reasoning, not just their labels. If you have the expertise to explain why something is categorized a certain way, not just that it is, DataAnnotation needs that judgment. Apply now.
The synthetic data problem
When teams can't get enough human-annotated data, they generate training examples synthetically. The reasoning seems sound: if you lack edge case examples, have an AI generate them.
Synthetic data doesn't just fail to solve transparency problems, it destroys them.
When a model trained on human-annotated data produces unexpected output, you can trace back through training examples. Synthetic data breaks this chain. You're debugging a model trained on examples from another model whose own training process you may not fully understand.
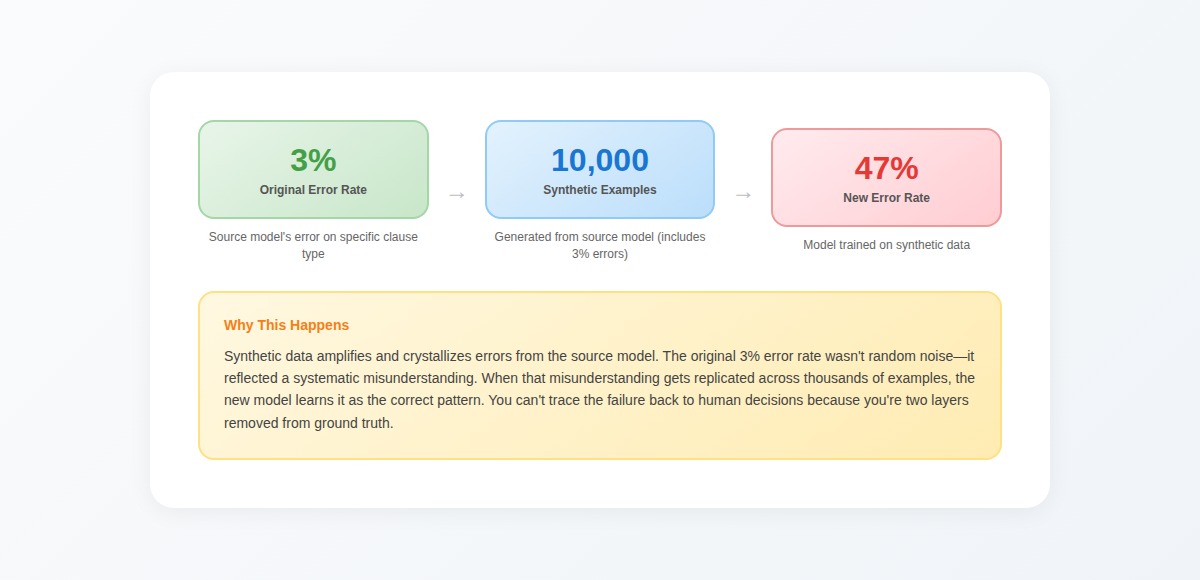
One team spent two weeks investigating why their contract analysis model consistently misclassified a specific clause structure. They traced it to synthetic examples encoding a subtle misinterpretation from the source model.
The original model had a 3% error rate on that clause type. After training on 10,000 synthetic examples including those errors, the new model's error rate jumped to 47%. Synthetic data amplified and crystallized the original confusion.
We analyzed datasets where 15-20% of synthetic examples contained hallucinations: citations to papers that don't exist, API parameters that were never real, mathematical proofs with subtle logical gaps. Models trained on this data don't distinguish grounded outputs from hallucinations; they produce both with equal confidence.
Each layer of synthetic generation is another curtain between you and ground truth. By the time a user sees an output, the chain of reasoning has passed through so many statistical transformations that "why" becomes unanswerable.
How to build real AI transparency
AI transparency emerges from how you build training data in the first place.
Document training decisions, not just outcomes
Most teams document what their model does, including accuracy scores, capability benchmarks, known limitations. Few document why it does those things.
Real transparency requires tracing from behavior to training decision:
- When the model fails on a specific input type, which training examples taught that pattern?
- When accuracy differs across categories, which annotation decisions created those differences?
- When the model handles edge cases well or poorly, which examples defined those boundaries?
This means building metadata that connects individual training examples to downstream model behavior, not just aggregate statistics that hide where problems concentrate.
Maintain human-annotated ground truth
Synthetic data severs the connection between model behavior and human judgment. Every layer of AI-generated training data makes the system harder to debug.
The teams that maintain transparency:
- Keep human-annotated examples as the foundation of training data
- Document the reasoning behind annotation decisions, not just the labels
- Use synthetic data only where they can validate it against human ground truth
- Track which training examples came from humans versus models
When something goes wrong, they can trace back to a human decision and understand why it was made.
Use expert examples that define boundaries
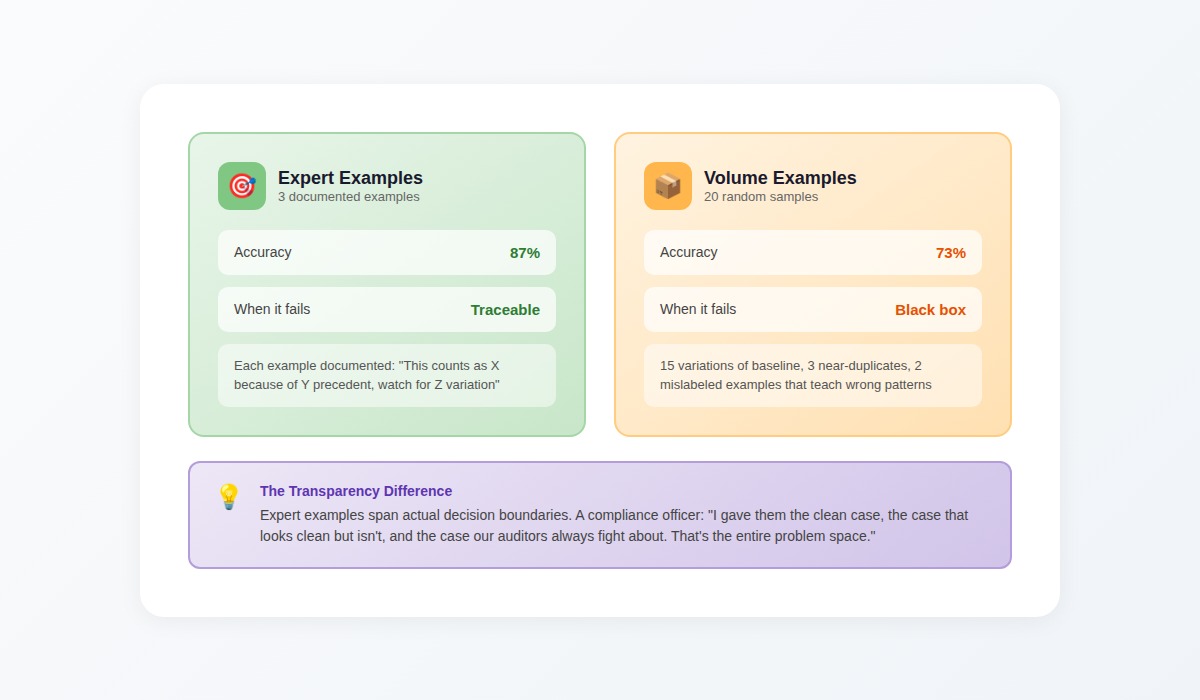
We ran controlled experiments across production deployments. Three expert-crafted examples with clear documentation consistently achieve 87% accuracy. Twenty random samples hover around 73%.
But here's what matters for transparency: when the expert-trained model fails, we can trace why. When the volume-trained model fails, we face statistical noise with no path back to human decisions.
A senior compliance officer put it this way: "I gave them the clean case, the case that looks clean but isn't, and the case our auditors always fight about. That's the entire problem space."
She knew which patterns mattered because she'd seen what edge cases cost when missed. Random sampling would never surface that knowledge; it gives fifteen variations of the baseline, three near-duplicates, and two mislabeled examples that teach wrong patterns.
Three expertly chosen examples can span actual decision boundaries you care about. Each one documented: "This counts as X because of Y precedent, watch for Z variation."
If you have domain expertise that lets you define boundaries and explain why, AI training at DataAnnotation puts that judgment to work.
Build queryable lineage
When a model produces concerning output, you should be able to query: "Show me the training examples most similar to this input. What were their labels? Who annotated them? What were the edge cases in this category?"
This requires infrastructure most teams don't build:
- Embedding-based similarity search across training data
- Annotation metadata linked to individual examples
- Version control for training data, not just model weights
- Audit trails showing how training data changed over time
The investment pays off when something goes wrong. Instead of guessing, you can identify exactly which examples taught the problematic behavior.
Monitor for drift
Transparency isn't a one-time achievement. Models drift as deployment contexts change, user behavior evolves, and the world shifts around your training data.
Track whether the inputs your model sees in production match what it saw in training. When they diverge, you know accuracy will degrade, and you know why.
Build feedback channels that surface problems: user reports, support tickets, downstream system failures. Route this feedback to teams who can investigate and generate corrective training data.
The teams that maintain transparent systems treat production feedback as continuous signal about what their training data got right and wrong.
Contribute to AI training at DataAnnotation
AI transparency starts in the training data. When companies can't explain why their model behaves a certain way, it's often because they can't trace decisions back to specific training examples, annotation patterns, or quality variations that shaped behavior.
That infrastructure depends on contributors who understand what they're evaluating—not people clicking through tasks to hit volume targets, but people with domain expertise to recognize edge cases, spot inconsistent labels, and provide nuanced feedback that makes model behavior interpretable downstream.
Technical expertise, domain knowledge, or the critical thinking to evaluate complex trade-offs all position you well for AI training work at DataAnnotation. Over 100,000 remote workers contribute to this infrastructure.
Getting started takes five steps:
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Starter Assessment—it tests critical thinking, not checkbox compliance
- Check your inbox for the approval decision (typically within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. DataAnnotation stays selective to maintain quality standards. The Starter Assessment can only be taken once, so read instructions carefully before submitting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI and have the expertise to contribute.
.webp)
JP is a software engineer turned digital marketer based in Texas. He graduated from the University of Texas at Dallas with a degree in Software Engineering and began his career as a fullstack developer in fintech. Drawing on his technical background, JP transitioned into digital marketing freelancing, where he combines his engineering expertise with creative strategy. He brings a unique blend of technical and marketing skills to the DataAnnotation team.
Related posts



Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.