


In this article
GPT-4 handles 128,000 tokens. Claude processes entire codebases. Gemini 1.5 ingests 1 million tokens per prompt. The context window arms race suggests more is always better: that longer context automatically means better performance.
Except it doesn't work that way in production.
Context length determines what a model can theoretically process. Context utilization, how effectively it actually uses that information, is the constraint that matters in production systems.
The gap between those two metrics is where most deployment problems live.
What is context length in AI?
Context length is the maximum number of tokens a language model can process in a single request. Think of it as the model's working memory, except that, unlike human memory, it doesn't prioritize.
Everything in the window gets equal billing, whether it's your critical instruction or irrelevant boilerplate from page 12. Context length and context window are used interchangeably; however, both refer to the same concept.
How models consume text
When you send a prompt to an AI model, the system converts everything into tokens: your instructions, examples, and the document to analyze. A token is roughly three-quarters of a word in English, though it varies significantly across languages and for specialized content.
In production, here's what actually happens. A model with a 100,000-token window receives a 60,000-token input, well within capacity. The first 10,000 tokens get substantial attention weight. The last 5,000 tokens get processed clearly.
The middle 40,000 tokens? The model's attention diffuses.
We call this the attention gap: the same factual claim placed at position 15,000 versus position 45,000 in an identical document produces different retrieval accuracy.
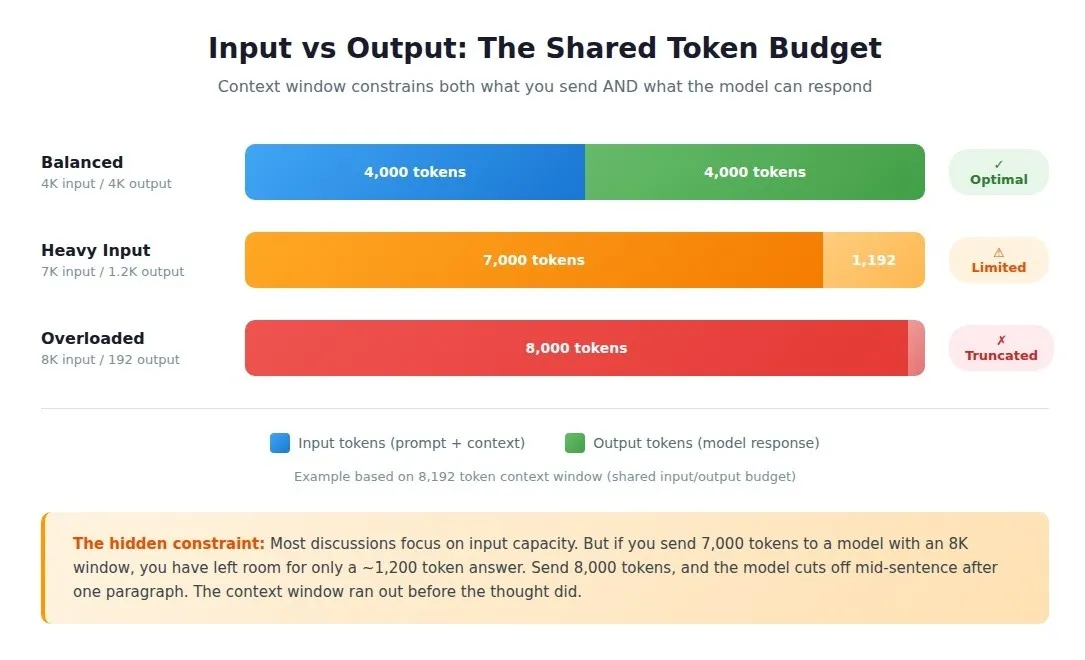
Input versus output token budgets
Most discussions focus on input capacity: how much text you can send.
But the context window constrains two separate quantities: the tokens you send in and the tokens the model generates in response.
For GPT-4 with an 8,192-token context window, if you send 7,000 tokens, the model has 1,192 tokens available for its response. Send 8,000 tokens, and you've left room for only a 192-token answer, about one paragraph.
Claude 3.5 handles this differently: separate limits for input (200,000 tokens) and output (typically 4,096 tokens). The total capacity was identical to that of other models. The usable capacity for specific tasks was not.
We've seen teams load prompts with 6,000 tokens of examples and instructions, then ask for a comprehensive analysis. The model cuts off mid-sentence. The context window ran out before the thought did.
What happens when you exceed context limits
When input exceeds a model's context window, one of three things happens: the API returns an error, the model silently truncates earlier content, or the system drops tokens from the middle.
Most APIs truncate from the start, which means your carefully crafted system prompt may disappear mid-conversation. You won't get a warning. The model simply loses access to content that no longer fits.
LLMs are stateless. They don't remember previous conversations. What appears to be memory is actually the full conversation history being resent with each message. When you hit the context limit, the model doesn't gradually "forget"; it simply loses access to content that no longer fits in the window.
Why context length determines what AI can actually do
Teams often hit the context limit mid-conversation and assume they hit a bug. The model worked perfectly. It answered follow-ups and maintained context. Then, suddenly, it started forgetting details from earlier in the thread. Nothing broke. They just ran out of tokens.
The difference between "can't fit" and "won't work reliably"
The obvious constraint is physical: if your input doesn't fit in the context window, you can't process it. But we see a more insidious problem: inputs that technically fit but still fail.
I worked on a team that processed quarterly financial filings for around 100k tokens using a 128k context model. It should have worked fine; they had 28k tokens of headroom. Yet the model kept missing critical disclosures due to the attention gap.
It paid attention to the beginning and end, where standard boilerplate lived, but lost focus on the substantive middle sections.
The constraint isn't just "what fits." It's "what fits and remains accessible to the model's attention mechanism across the entire sequence."
Tasks that become possible at different thresholds
Context length doesn't just limit how much you can process; it determines which tasks are viable.
At 4k tokens (early GPT-3 era), you could do single-document summarization and simple Q&A. Multi-turn conversations hit limits after a few exchanges. At 32k tokens, entire categories opened up: full codebase analysis, research paper review with references, and longer conversation histories. At 128k tokens, another shift: complete contract review and multi-document comparison.
One team switched from chunking medical records across multiple API calls to sending complete patient histories in a single prompt. Their diagnostic accuracy support jumped by 23% because the model could see temporal patterns across years of data rather than fragmented snapshots.
These thresholds are task-specific and unpredictable until you test them. Context length creates discrete phase transitions where entire use cases flip from "impossible" to "viable." Those thresholds vary by task in ways that aren't obvious from specifications.
Why "just chunk it" doesn't solve the problem
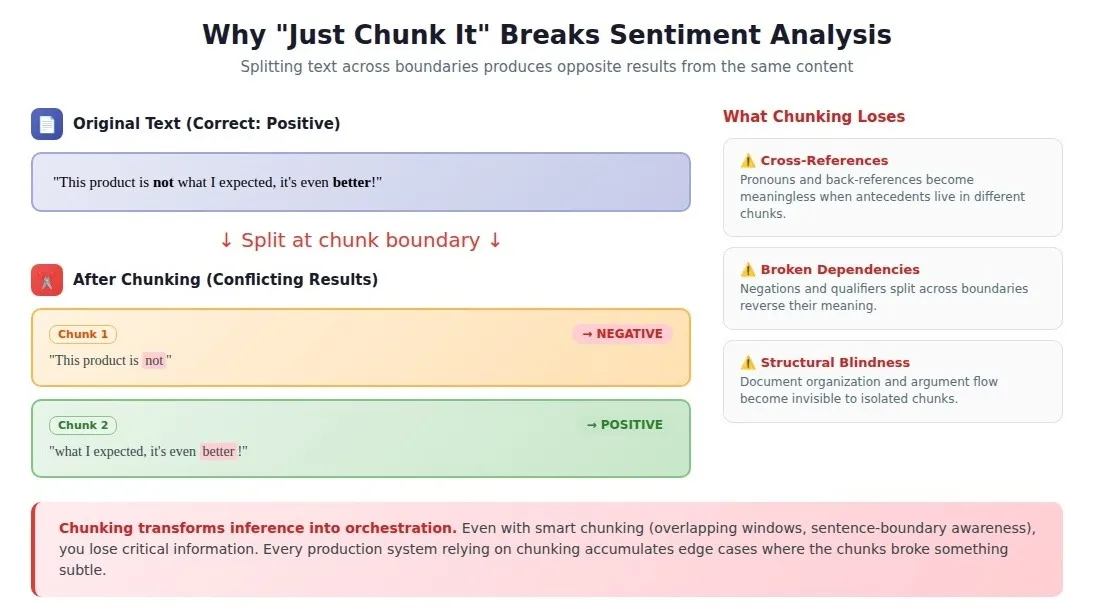
The standard workaround when you hit context limits is chunking: split your input into smaller pieces, process each separately, and combine results. It's the obvious solution. It's also where most implementations start accumulating duct tape.
A debugging session revealed why one team spent two weeks on inconsistent sentiment analysis: their chunking strategy split sentences across boundaries. The model would see "This product is not" at the end of one chunk and "what I expected, it's even better!" at the start of the next. Each chunk analyzed independently produced opposite sentiments.
Even with smart chunking (overlapping windows, sentence-boundary awareness), you lose critical information: cross-references, long-range dependencies, structural relationships. Chunking transforms a single inference problem into an orchestration problem.
Every production system I've seen that relies heavily on chunking has a backlog of edge cases where the chunks broke something subtle.
Where long context windows break down
The marketing materials say the model handles 128K tokens. The benchmark shows 92% accuracy on a long-form Q&A. Then you deploy it, and it misses critical information on page 47 of a technical specification.
The disconnect follows predictable patterns.
The "lost in the middle" problem is worse than published research suggests
Models perform best on information at the beginning and end of their context window, with degraded attention to content in the middle. What we've observed in production is that this degradation isn't gradual; it's precipitous and inconsistent.
We worked with a team that processed insurance claim documents. When the relevant exception appeared in the first 20% or last 15% of the context, extraction accuracy sat around 89%.
When that same exception appeared between the 35% and 65% marks, accuracy dropped to 61%. Same model, same task, same information, just positioned differently.
The problem compounds with document length. At 8K tokens, we see maybe a 10-15% accuracy gap between edge and middle content. At 64K tokens, that gap can exceed 40%. Benchmarks miss this because they test with carefully curated documents where relevant information is strategically positioned. They also average performance across positions, thereby they obscure the severity of the problem.

The benchmark vs. production gap
Standard benchmarks like "Needle in a Haystack" test something no production system actually needs: retrieving a single, artificially planted fact from otherwise meaningless text. It's the AI equivalent of testing a chef by asking them to find a hidden ingredient in a pantry, then declaring them ready to run a kitchen.
Production tasks demand more: information synthesis across multiple sections, consistent reasoning about complex entities, and inference from context at different positions.
A model can tell you what was said in the March meeting minutes and what was decided in June. It has much more difficulty assessing whether the June decision contradicts the March discussion, a task that requires tight attention across both contexts simultaneously.
Benchmarks also test with clean, well-structured documents. Production data is messy: inconsistent formatting, nested structures, embedded tables, and ambiguous references. We've seen models that score 90%+ on benchmark long-context tasks drop to 70% accuracy when processing real documents with complex schedules and cross-references.
Most critically, benchmarks test average-case performance. Production requires tail-case reliability. If your document analysis is correct 93% of the time, the 7% where it misses a material obligation is what generates liability.
The quality problem: why longer context doesn't mean better results
The teams that struggle most with long context windows aren't the ones hitting technical limits; they're the ones who assumed more context would solve their quality problems.
The retrieval quality ceiling
When a team tells us their RAG system doesn't work despite "plenty of context," the first thing we check isn't the window size; it's what actually gets retrieved.
We worked with one team whose medical record analysis produced inconsistent classifications. They'd upgraded to a 128k context window and fed it the top 50 retrieved chunks per query. The problem was that chunks 11-50 were actively misleading: fragments of unrelated cases, notes that contradicted the specific conditions that mattered.
The solution wasn't a bigger context window. It was a better retrieval. When they improved their embedding model and retrieval logic to surface fewer but more relevant chunks, accuracy jumped from 73% to 91%. Same model, same context window, one-third the amount of text. More capacity doesn't compensate for poor judgment about what to include.
The annotation paradox
As context windows get longer, the annotation work required to achieve reliable performance becomes exponentially more complex.
When you work with 4k token contexts, an annotator can hold the entire context in their head to make a judgment. We've timed this: an experienced annotator, someone who's spent years developing judgment about what matters in text, can evaluate a question-answer pair against a 4k context in 3-5 minutes with high consistency.
At 32k tokens, that breaks down completely. Nobody can hold 32k tokens in working memory. What took 3-5 minutes at 4k tokens takes 15-25 minutes at 32k tokens. And inter-annotator agreement falls from 94% on 4k contexts to 76% on 32k contexts for the same task type.
The brutal reality: if you can't annotate it reliably, you can't train on it reliably. And if you can't evaluate it reliably, you have no idea if your model actually works.
How context length shapes the data AI models need
The attention dilution, retrieval failures, and quality degradation aren't inevitable. They're symptoms of models trained on data that doesn't teach them what to do with all that space.
Training data needs to demonstrate the behaviors you want
The industry assumes that training a model on long documents automatically teaches it to use long context well. This is the same logic that says reading a thousand novels makes you a novelist.
A model trained on thousands of full research papers learns to predict the next token. It doesn't automatically know to find the three relevant sentences buried on page 47, synthesize arguments across sections, or notice when two distant paragraphs contradict each other. Those are distinct capabilities that require distinct training examples.
One team that built a model for legal contract analysis had many long contracts in its training data. But when deployed, it performed well on standard clause extraction and poorly on everything else.
We rebuilt their training set with examples that explicitly demonstrated three behaviors: find the related clauses across sections, identify the conflicts between terms, and track the defined terms through usage across the document.
Same document lengths, completely different behaviors encoded.
Quality matters exponentially more in a long context
I watched a researcher spend three hours on a single training example for a financial analysis task with a 40,000-token earnings transcript. She read the entire transcript, tracked multiple threads of reasoning, verified her work against source material, and documented her process.
Three hours. One example. And it was worth it: that single high-quality example taught the model a pattern that dozens of lower-quality examples hadn't.
This is what quality looks like at scale: not faster annotation, but deeper understanding per example.
Contribute to AGI development at DataAnnotation
The context limitations shaping frontier AI models reveal a fundamental truth: training data that teaches models what to prioritize, what to retain, and what context actually matters.
The training data that improves context utilization comes from human experts who understand which details matter, how information connects across long contexts, and what reasoning patterns separate coherent responses from plausible-sounding nonsense.
If your background includes technical expertise, domain knowledge, or the critical thinking to evaluate complex trade-offs, AI training at DataAnnotation positions you at the frontier of AGI development.
Over 100,000 remote workers have contributed to this infrastructure. If you want in, getting from interested to earning takes five straightforward steps:
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking skills
- Check your inbox for the approval decision (typically within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. You can only take the Starter Assessment once, so read the instructions carefully and review before submitting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI, and you have the expertise to contribute.
Frequently asked questions about context length
How many words are 128K tokens?
Approximately 96,000 words, or roughly the length of a novel. One token equals about 0.75 words in English, though this varies for code, technical content, and non-English languages.
Does longer context length mean better AI performance?
Not automatically. The industry treats context length like a spec sheet number: bigger is better. But models lose information in the middle of long inputs, a phenomenon known as the "lost in the middle" problem.
What's the difference between context length and AI memory?
LLMs don't have persistent memory. Context length is the working memory for a single request. The full conversation history must be resent with each message. When the conversation exceeds the context limit, earlier content is lost.
.webp)
JP is a software engineer turned digital marketer based in Texas. He graduated from the University of Texas at Dallas with a degree in Software Engineering and began his career as a fullstack developer in fintech. Drawing on his technical background, JP transitioned into digital marketing freelancing, where he combines his engineering expertise with creative strategy. He brings a unique blend of technical and marketing skills to the DataAnnotation team.
Related posts


Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.