


In this article
A developer showed me two API calls to the same model, identical prompts. One response was creative and useful. The other was repetitive nonsense. They were confused because they changed nothing, or so they thought.
Then I asked about their sampling parameters. There it was: k=50 in one call, k=5 in the other.
Top-k sampling sits at the center of a problem most teams never examine. It's one of the most common decoding strategies in production systems, but practitioners treat it as a magic number to copy from someone else's config file. Every top-k value is a bet on what "good" means, and most teams never examine the bet.
What gets lost: top-k sampling doesn't just affect output quality. It fundamentally changes what your model does at inference time, and what your evaluation results actually measure.
What is top-k sampling?
At every generation step, a language model assigns probabilities to its entire vocabulary: tens of thousands of tokens, each with a likelihood score. The model doesn't "know" what word comes next. It has degrees of belief spread across thousands of possibilities.
Top-k sampling imposes a hard constraint on that uncertainty. Keep the k most probable tokens. Zero out everything else. Renormalize probabilities across what remains, then sample.
How does top-k sampling work?
The mechanic is simple. The implications are not.
When k=10, the model samples only from its top 10 predictions. Token 11, no matter how plausible, is excluded entirely. When k=50, fifty options remain in play. The difference isn't just scale; it determines whether the model can access the edges of what it knows or stays locked to its most confident guesses.
This matters because probability distributions aren't shaped the same way across prompts.
- Sometimes the model is confident: one token dominates at 70%, while the rest barely register.
- Other times, the model is genuinely uncertain: the top five tokens each carry 10-15% probability, and meaningful options extend into the hundreds.
Top-k treats both situations identically, truncating at k regardless of whether that cutoff falls through noise or signal.
A 200-token response involves 200 of these decisions. Each truncation shapes what the model can say next, and each choice propagates forward.
The arbitrary line you draw at token selection becomes the boundary of what your model is allowed to express.
How top-k shapes output variance
We track output variance across repeated runs because it tells us whether a configuration is production-ready:
- At k=1, you get deterministic outputs (this is actually greedy decoding)
- At k=5, outputs stay remarkably similar across runs
- At k=50, variance explodes
We measured one customer's summarization endpoint: k=50 produced outputs that varied in length by 40% across identical inputs. Vocabulary spanned from clinical precision to borderline informal. The model occasionally inserted phrases that felt completely off-brand completely.
The tradeoff isn't just about variety; it's about exposure to the model's uncertainty.
- Low top-k values hide the fact that the model might be equally uncertain about five different continuations.
- High top-k values surface that uncertainty, but also give the model enough rope to wander into territory you didn't expect.
Top-k vs. greedy decoding, beam search, and nucleus sampling
Every decoding method is a different bet on the same tradeoff: determinism versus diversity. The interesting part isn't which method is "better." It's how they fail differently under pressure.
Greedy decoding: consistency at the cost of edge cases
Greedy decoding always picks the single token with the highest probability. No randomness, no alternatives considered. Teams default to greedy for classification tasks and structured extraction, anything where consistency matters more than novelty. The failure mode is predictability.
If the model makes a mistake with greedy decoding, it makes the same error every time. A contracts attorney with 12 years in M&A, turned ML lead at a legal tech startup, spent a month debugging why their model consistently misclassified a specific contract type. When they switched to top-k=10, the model occasionally took different reasoning paths and caught edge cases it had been missing.
Beam search: quality gains with latency costs
Beam search maintains multiple candidate sequences, scores all of them, and keeps the highest-scoring options alive. The operational cost is real: beam search with a width of 5 can add 3-5x latency.
The more interesting failure mode: beam search tends to produce safe, generic outputs. It optimizes for probability, and high-probability sequences are often bland.
Nucleus sampling (top-p): adaptive but unpredictable
Nucleus sampling addresses top-k's rigidity by setting a cumulative probability threshold rather than a fixed token count.
Set top-p=0.9, and the model considers however many tokens are needed to reach 90% cumulative probability: sometimes 5 tokens, sometimes 50. This adapts naturally to the model's confidence.
The operational challenge is that nucleus sampling behavior is harder to predict. A content marketing team at a B2B SaaS company evaluated their blog generation system using top-p=0.9.
Quality scores varied wildly between test runs. When they switched to top-k=40, evaluation variance decreased by 30%.
Choosing by failure mode, not "best" method
The question isn't which sampling method is "best"; it's which failure modes you can tolerate.
The cutoff problem: where top-k fails
A senior ML engineer at a fintech company noticed a pattern: their customer service bot would generate perfectly coherent responses 90% of the time, then suddenly produce near-nonsense for the remaining 10%. The root cause: their k=40 configuration is hitting different distribution shapes.
When the model was confident about common queries, the top 5-10 tokens contained most of the probability mass, and k=40 worked fine. But when it encountered edge cases, the probability distribution flattened. Now, the k=40 cut-off tokens collectively held 30-40% of the probability mass.
We tested this by logging cumulative probability across thousands of generation steps. In high-quality outputs, k=40 captured an average of 94% of probability mass. In failure cases, it captured only 68%.
Same top-k value, same model, same prompt structure, but completely different practical constraints on generation.
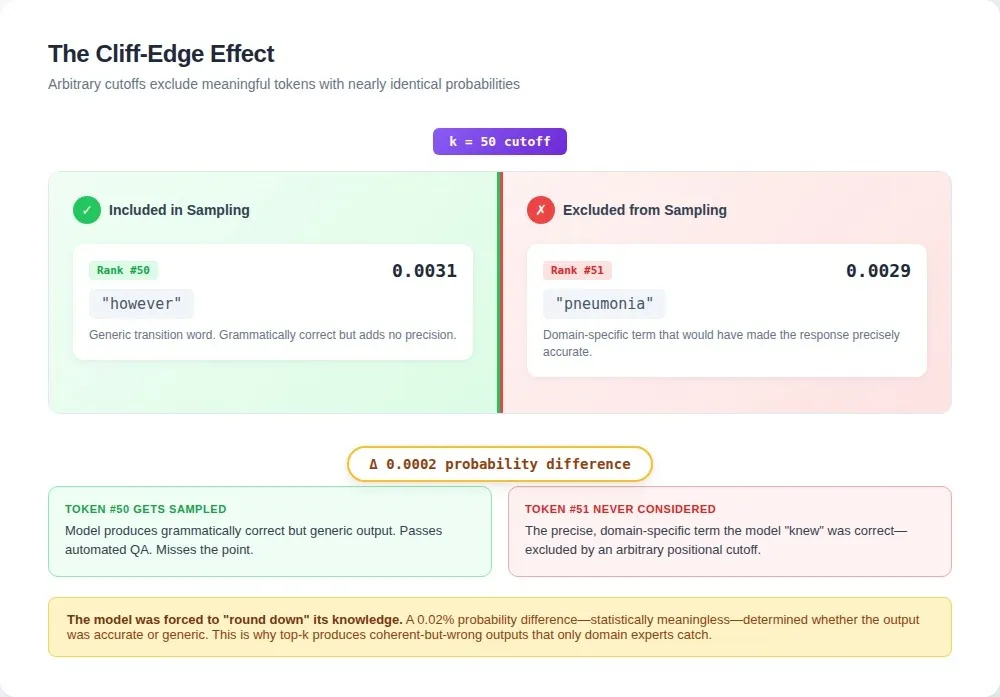
The cliff-edge effect
One stubborn bug traced back to this scenario: token 50 had probability 0.0031, token 51 had probability 0.0029. Nearly identical likelihoods, but one was included in sampling, and the other was completely excluded.
Token 50 was a generic transition word. Token 51 was a domain-specific term that would have made the response precisely accurate. The model was forced to "round down" its knowledge because of where the cutoff fell.
Multimodal distributions fragment coherent choices
The most insidious failure mode occurs when probability distributions are multimodal: multiple clusters of reasonable tokens separated by low-probability regions. Fixed top-k values can split these clusters in pathological ways.
This surfaced clearly in a Python refactoring task that converted legacy data processing scripts. The model needed to choose between list comprehension and a traditional for loop. Both were correct, and the probability distribution reflected this. Tokens for list comprehension syntax clustered around ranks 3-15. Tokens for for-loop syntax clustered around ranks 25-40.
With k=20, the system consistently started list comprehensions but couldn't complete them properly because the later tokens for that approach were cut off. The model would begin with the opening bracket, then get forced into a for-loop token because that was the only option remaining in the top-20.
A backend engineer with a decade of Python experience caught it in the first batch: the code wasn't wrong; it was just wrong in that no human wrote it. The probability distribution was trying to tell us something coherent, but k=20 fragmented it.
Fixed-k sampling assumes the model's uncertainty has a clean boundary. Keep the top 50 tokens, discard the rest. Problem solved. But uncertainty doesn't work that way.
The model's probability distribution tells you something about the shape of the problem: how many valid paths exist, where the knowledge gets thin, and when confidence is real versus when it's performed.
Top-k draws a rectangle around that signal and throws away everything outside the line.
Top-k values for extraction, generation, and multi-turn conversations
You can't tune top-k in isolation, and there's no universal setting that works everywhere. What matters is matching the parameter to what your application actually needs.
Structured extraction: k=3 to k=10
Most engineers assume k=1 or greedy decoding for deterministic tasks. This fails repeatedly. One team extracted contract clauses using k=1. They got a perfectly consistent output format and consistently missed specific clause types.
The model had learned a strong prior toward common contract language. With k=1, it never escaped that prior. Moving to k=5, accuracy on rare clause types jumped 23%.
You're not enabling creativity at k=5 or k=10. You're giving the model room to route around its own priors when the input demands it.
Creative generation: k=40 to k=60
Teams push top-k values to 100 or higher to chase variety, then wonder why the output becomes incoherent. The problem isn't the high value itself; it's that high top-k exposes every other weakness in your setup.
Experiments across top-k values from 10 to 200 showed: below k=30, outputs felt the same; above k=80, coherence breaks appeared. The sweet spot sat between k=40 and k=60 for most long-form generation. But creative generation needs temperature adjustment alongside k. With k=50 and temperature=0.7, you get varied but coherent output. Same k=50 with temperature=1.2, and you're pulling too heavily from low-probability regions.
Domain-specific applications: k=10 to k=30
Medical, legal, and technical domains need accuracy more than variety. But they also need the model to recognize when domain-specific terminology should override general language priors.
A clinical informaticist we work with, with 15 years of experience in physician notes and board certification in health informatics, used k=10 for clinical note generation.
She'd chosen conservative parameters deliberately: in medical contexts, plausible-but-wrong is more dangerous than obviously-wrong. The model performed fine on common diagnoses.
Then she started reviewing outputs for edge cases herself, applying the diagnostic pattern-matching she'd developed over a decade. She caught substitutions that automated QA missed entirely: the model defaulting to "acute respiratory infection" when the context indicated "aspiration pneumonia." Both terms would pass a grammar check. Only domain expertise knew the difference mattered.
Widening to k=30 helped, but only when the prompt provided enough domain context. With minimal context, k=50 gave worse results than k=10. With rich context, k=50 improved specialized term accuracy by 31%.
Multi-turn conversations: dynamic values as context grows
Multi-turn conversations expose something single-turn generation hides: top-k requirements shift as context accumulates. Teams set values based on initial testing with 3-5-turn examples, then receive reports of conversations drifting after extended exchanges. Starting at k=50 and dropping to k=30 by turn 10 addresses this pattern.
Why your evaluation results don't match production
Here's what becomes clear after debugging dozens of "model regression" incidents: parameter settings matter far less than teams think.
What looks like model performance problems are actually measurement inconsistencies: teams comparing results across different configurations without realizing they're measuring entirely different things.
One team spent two weeks optimizing their prompt for customer support classification, only to find that their new version performed worse than the baseline.
They'd improved accuracy from 76% to 81% in their tests, but production showed the opposite pattern. The culprit wasn't the prompt: they'd changed sampling parameters between test runs without documenting it.
Their "improved" prompt used a temperature of 0.7 with top-k=40, while production ran the original at a temperature of 0.3 with top-k=10. They weren't comparing prompts at all.
Generation parameters act as hidden variables that invalidate most comparative evaluations. The same model with the same prompt showed a 12-point accuracy swing just from changes to top-k between 10 and 50 at temperature 0.8.
That's larger than the typical improvement teams see from hours of prompt iteration. Yet sampling parameters rarely appear in evaluation reports.
This is how benchmark theater works in practice. Teams report accuracy improvements without reporting the sampling configurations that produced them. The leaderboard goes up. The paper gets published. And nobody can reproduce the results because the "model" they evaluated was actually a model-plus-parameters system that existed only during that test run.
Why synthetic evaluation fails
You can generate a million preference pairs, but if the preferences don't reflect genuine quality distinctions, they're just statistical patterns in existing outputs. You're training the model to optimize for artifacts of your generation process, not actual quality.
Human judgment isn't just more expensive. It's categorically different. Synthetic data can tell you what's probable. Only human evaluation can tell you what's good.
Valid comparison requires parameter discipline
We now maintain sampling parameter manifests for every evaluation, a documented record of every generation setting:
- Temperature
- Top-k or top-p
- Presence and frequency penalties
- Any repetition controls
- Random seed when possible
- Exact API version or model checkpoint
When we evaluate prompt variations, all of these stay fixed. Even perfect parameter discipline bottlenecks on one thing: the humans evaluating outputs that surface from expertise.
Contribute to AGI development at DataAnnotation
When you adjust top-k values from 50 to 40, someone has to assess whether the outputs actually improved or just changed. That evaluation work, at scale, is what trains models to generate better text in the first place.
That judgment is the irreducible human element. You can tune parameters forever. Eventually, wisdom has to enter the system, and it doesn't come from the model.
Every sampling method is a bet on what the model knows. Human judgment is how you collect on it.
If your background includes technical expertise, domain knowledge, or the critical thinking to evaluate complex trade-offs, join the 100,000 remote workers who have contributed to this infrastructure.
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking skills
- Check your inbox for the approval decision (typically within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. You can only take the Starter Assessment once, so read the instructions carefully and review before submitting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI, and you have the expertise to contribute to it.
.webp)
JP is a software engineer turned digital marketer based in Texas. He graduated from the University of Texas at Dallas with a degree in Software Engineering and began his career as a fullstack developer in fintech. Drawing on his technical background, JP transitioned into digital marketing freelancing, where he combines his engineering expertise with creative strategy. He brings a unique blend of technical and marketing skills to the DataAnnotation team.
Related posts


Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.