


In this article
Most companies design their AI training infrastructure backward.
They start with throughput architecture — how many annotations per hour, how many workers per project, how many examples they can generate. Then they discover quality is the actual bottleneck.
Task completion rates look great, but model performance plateaus or regresses. They spend months discarding data and rebuilding measurement systems.
We see this pattern constantly. Companies come to us after generating millions of synthetic examples and later realize that a large percentage need to be thrown out. They assumed scale would solve quality. It never does.
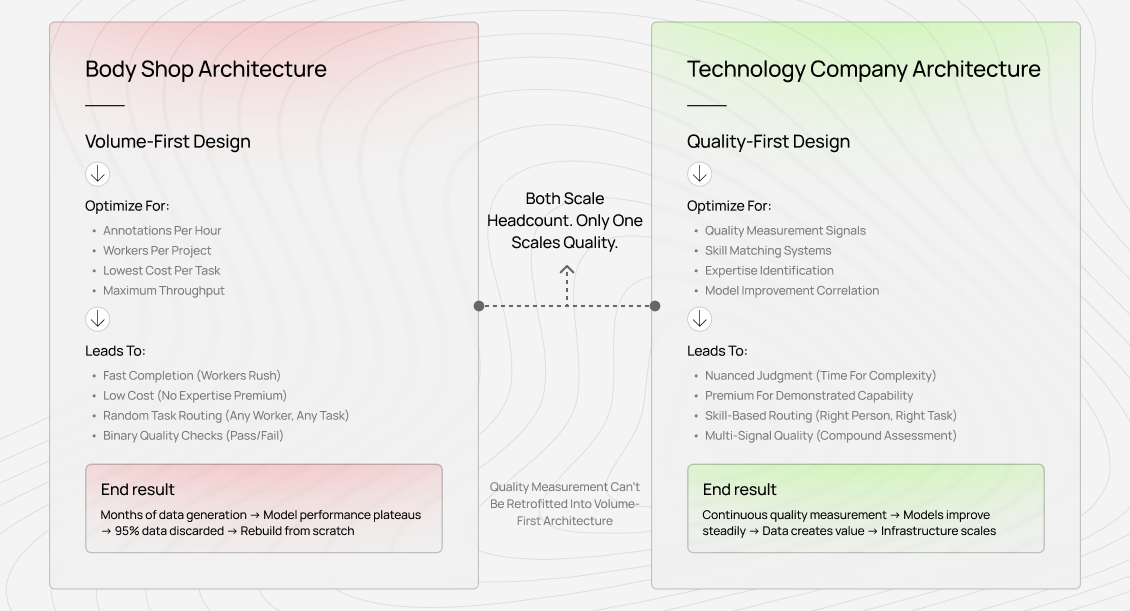
The architecture decision you make at the beginning determines what you're building: a body shop that scales headcount, or a technology company that scales quality infrastructure. Most scaling guides focus on the first. This one focuses on the second.
1. Start with quality measurement, not data volume
The actual bottleneck in AI training infrastructure isn't throughput. It's quality measurement that scales. The architecture decisions you make in the first few months determine whether you succeed or not.
The throughput-first approach feels intuitive. Build pipelines that handle millions of examples. Hire workers quickly, generate data fast, and measure quality later.
This fails for a simple reason: you can't retrofit quality measurement into volume-first architecture.
Why volume-first architecture breaks
When you design for throughput, you optimize for:
- Fastest task completion times
- Lowest cost per annotation
- Maximum worker utilization
- Simple binary quality checks
These metrics actively work against quality:
- Fast completion means workers aren't spending time on nuanced judgments
- Low cost means you're not paying for expertise
- Maximum utilization means you're routing any available worker to any available task, ignoring skill matching
- Binary checks mean you're measuring "did they follow instructions," not "did they teach the model something valuable."
We've seen companies spend months building volume infrastructure, then discover their models trained on this data perform worse than baseline. The data technically meets specs — correct format, follows guidelines, passes validation.
But it doesn't improve models because the throughput architecture optimized for the wrong thing.
The 99% discard pattern
Here's what happens in practice: A lab generates millions of synthetic training examples. Throughput looks amazing — they're producing data faster than any human workforce could. Then they run evaluations. The model performs worse on real-world tasks while excelling on narrow benchmark problems.
They spend months analyzing what went wrong. Eventually, they realize the synthetic data collapsed model behavior into patterns that look impressive but lack genuine diversity. They keep 5% of examples that still look human-like. Discard the rest. Then they contact us for actual human data.
The issue wasn't the synthetic data itself. It was architecture that assumed that volume equals quality, when the relationship runs in the opposite direction.
Build quality infrastructure first
Quality-first architecture starts with different questions:
What signals indicate high-quality work? How do you measure quality at the resolution that matters — not binary pass/fail, but the subtle differences between competent annotation and exceptional annotation that actually teach models new capabilities?
Can you identify which workers excel at which types of tasks? A PhD in English literature might not write better poetry than someone who never finished college. How does your system discover this?
How do you preserve these quality signals as you scale from 10 workers to 100,000? Most manual measurement approaches break at scale.
If you can't answer these questions before building data pipelines, you're optimizing for the wrong bottleneck.
2. Build your quality signals before your data pipeline
Most AI training platforms treat quality as a filtering problem: collect data, then remove the bad stuff. This is backward.
Quality measurement needs to be the foundation your data pipeline builds on top of, not something you bolt on afterward.
Define quality at high resolution
The first mistake companies make: treating quality as binary (good/bad) or even ordinal (1-5 stars). This works for commodity tasks like image labeling. It fails completely for the complex work that improves frontier models.
When we measure quality, we're asking:
- Does this annotation teach the model something it couldn't learn elsewhere?
- Is it creative in ways that synthetic data can't capture?
- Does it demonstrate edge-case reasoning that comes from genuine expertise?
These questions don't reduce to checkboxes. They require multiple signals that compound into a nuanced quality assessment.
The signals to use
I'll be specific about what quality measurement looks like in production:
Real quality infrastructure captures signals automatically, not manually.
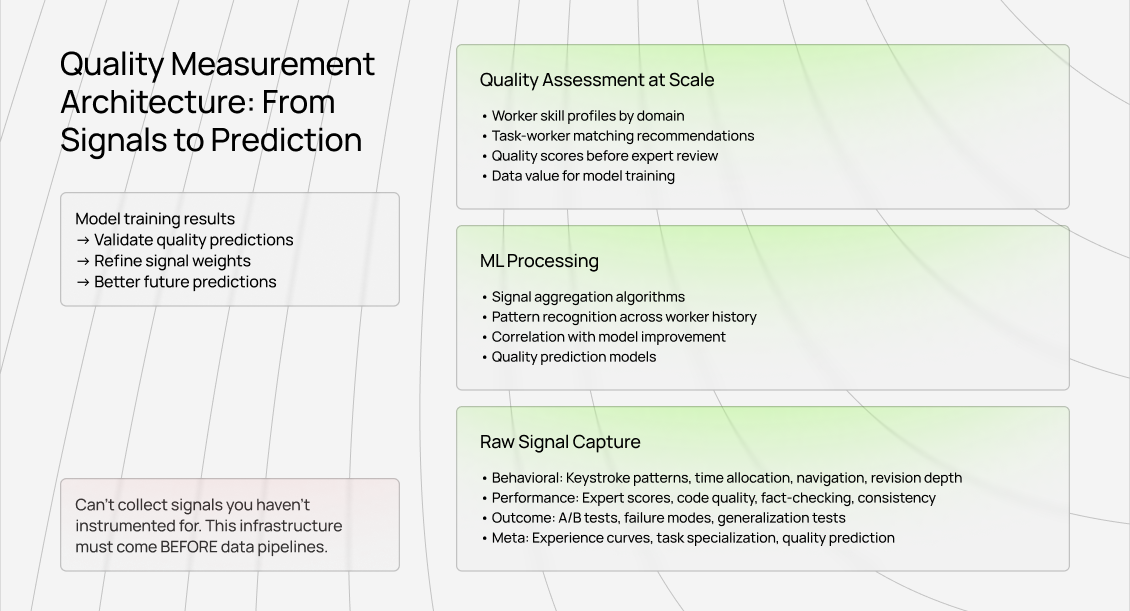
Architecture similar to search ranking
This is fundamentally similar to how Google ranks search results. You can't manually review millions of web pages and assign quality scores. You need thousands of signals feeding into ML algorithms that predict quality at scale.
The difference: search engine quality is measured by user behavior (clicks, dwell time, bounce rate). Training data quality is measured by model improvement. The measurement is more complex because the feedback loop is longer and more indirect.
But the architectural principle is identical: gather massive amounts of signals, train high-quality prediction models with them, and deploy those models to evaluate new data at scale.
Why must this come before pipelines?
You can't collect signals you haven't instrumented for. If your data pipeline doesn't capture keystroke patterns because you never thought they'd matter, you can't retrofit that measurement later without rebuilding the entire system.
This is why quality infrastructure must come first. You're making architectural decisions about which data to preserve, which signals to measure, and which analyses to support. These decisions are nearly impossible to change once production workloads are running.
3. Design for skill differentiation, not worker fungibility
The commodity annotation model assumes all workers are interchangeable. Give anyone the exact instructions, and they'll produce the same output. This works for drawing bounding boxes around cars. It catastrophically fails for everything that matters in AI training today.
Why standardized instructions produce non-standardized results
Take a simple task: "Write an eight-line poem about the moon."
A high school student will check boxes — eight lines, mentions the moon, and follows a basic rhyme scheme. A PhD in English literature will also check those boxes. But the PhD's poem will demonstrate internal rhyme, sophisticated imagery, emotional depth, and linguistic subtlety that the high school version lacks entirely.
Both technically "passed" the instructions. One is training material for a frontier model. The other is training material for mediocrity.
The difference isn't effort or compliance; it's accumulated expertise that can't be transmitted through instructions. And this gap exists in every complex domain.
Code quality, mathematical reasoning, medical judgment, legal analysis; expertise creates massive output variance that standardized processes can't eliminate.
The skill routing problem
If workers aren't fungible, your infrastructure needs to route work based on demonstrated capability, not just availability. This means maintaining skill profiles that go deeper than resume checkboxes.
Your system needs to know:
- Which workers consistently handle edge cases correctly in specific domains
- Who demonstrates sophisticated reasoning versus pattern matching
- Whose work improves model performance when it enters training
- Which types of tasks does each worker excel at or struggle with
This isn't about creating arbitrary tiers. It's about ensuring that expert-level tasks go to people with expert-level capabilities, measured by output quality rather than claimed credentials.
Credential validation through performance
I've seen platforms hire exclusively from top universities, assuming credentials guarantee quality. Then they're surprised when their MIT CS graduates produce mediocre code annotations.
Having a degree means you passed certain tests. It doesn't mean you're good at teaching frontier AI systems through data. The only reliable validation is performance measurement over time.
Your infrastructure should track quality signals continuously and route work accordingly. If someone with a bachelor's degree consistently produces better medical annotations than someone with an MD, that's what your routing system should optimize for.
Credentials might predict initial performance. Demonstrated capability should determine ongoing assignments.
3. Treat data pipelines as bi-directional feedback systems
Most pipeline architectures are one-way: data flows from collection to training. This is efficient but blind. You're feeding data into models without knowing whether it's improving them, worsening them, or just adding noise.
The model performance feedback loop
Your data pipeline needs reverse flow: model performance signals should propagate back to data collection decisions. When specific annotation patterns consistently improve model capabilities, you want more of that work from those annotators.
When other patterns correlate with performance degradation, you want to understand why and adjust.
This requires instrumentation at both ends:
On the training side: Track which data batches correlate with capability improvements in specific domains. Not just "did loss decrease" but "did the model get better at edge case handling in medical diagnosis," or "did code generation improve for error handling scenarios."
On the collection side: Tag every annotation with worker ID, task type, difficulty level, and quality signals. When training teams report that specific batches hurt performance, you can trace back to particular workers or annotation methodologies.
The goal isn't to blame workers when things go wrong. It's to create a learning system where data-collection methodology improves based on what actually helps models, not on what seems theoretically correct.
Quality measurement as a training signal
Here's something most platforms miss: quality measurement infrastructure can become training infrastructure. The same signals you use to evaluate annotator performance can help annotators improve.
If you're tracking that someone consistently misses edge cases in medical annotations, that's actionable feedback. If you're measuring that their code evaluations don't align with what actually improves model performance, they can learn from examples that do.
This transforms data collection from execution (do what you're told) to skill development (improve at what matters). The workers who contribute most to AGI development are the ones actively improving their judgment through feedback, not just following static instructions.
The anti-pattern: optimizing for the wrong metrics
I've watched platforms optimize their pipelines for speed, then wonder why model performance stays flat. They measure annotations per hour, time to completion, and worker throughput. All their metrics trend upward while their training outcomes don't improve.
The problem is optimizing for efficiency before validating effectiveness. If you don't know whether your current methodology produces useful training data, making that methodology faster just scales the problem.
Build feedback loops first. Measure whether your data improves models. Then optimize for efficiency once you know what "good" looks like.
4. Architect for complexity expansion, not just volume growth
Your infrastructure will need to handle more annotations over time. That's obvious. What's less obvious: it will need to handle exponentially more complex annotations that require entirely different evaluation methodologies.
The complexity timeline
In 2020, AI training data was mostly straightforward: classify images, label text, transcribe audio. Quality meant accuracy: did you identify the right object, extract the correct information?
Now, frontier model training requires annotators to evaluate complex reasoning chains, identify subtle errors in generated code, assess whether AI responses demonstrate genuine understanding or pattern-matching, and provide nuanced feedback on multi-step problem-solving.
The difference isn't just more complex tasks. It's tasks where "correct" isn't binary, where domain expertise creates massive output variance, and where quality measurement requires sophisticated judgment rather than checklist compliance.
Infrastructure that adapts to new task types
Your architecture needs to accommodate the task complexity you haven't yet designed for. This means building abstraction layers that separate task-specific logic from core quality measurement infrastructure.
When a new task type emerges (say, evaluating AI reasoning in novel scientific domains), you shouldn't need to rebuild your quality measurement system. You should be able to define new signal types, new evaluation criteria, and new skill requirements without touching your core architecture.
This is the difference between platforms that can rapidly support emerging AI capabilities and platforms that lock you into 2023-era task types because the infrastructure is too rigid to evolve.
The talent pipeline problem
As tasks get more complex, you need access to deeper expertise. Your infrastructure should enable quality scaling through skill development, not just through hiring more people.
This means building:
- Progressive difficulty systems that let workers advance to more complex tasks as they demonstrate capability
- Skill-specific training pathways based on where models need improvement
- Quality feedback that actually develops expertise rather than just measuring compliance
- Compensation structures that reward expertise development, not just volume completion
The platforms that will support AGI development are those that treat AI trainers as skilled professionals whose expertise compounds over time, not as commodity labor executing standardized processes.
5. Build for quality variance, not quality averages
Most infrastructure is designed around achieving consistent quality; get everyone to meet the same standard. This makes sense for commodity work. For AI training, it's the wrong goal.
Why you want quality variance (in the right direction)
The annotations that most improve frontier models aren't the ones that meet minimum standards. They're the exceptional examples that demonstrate deep understanding, handle novel edge cases, or capture nuance that standard approaches miss.
If your infrastructure is optimized to make everyone produce B-level work, you're eliminating the A+ examples that create breakthroughs. You want consistent filtering of poor work (eliminate the Ds and Fs), while preserving and amplifying exceptional work (discover and scale the A+ examples).
The discovery problem
Exceptional work is rare by definition.
If you're manually reviewing 5% of outputs, you'll miss most of it. Your infrastructure needs automated discovery mechanisms that surface the best examples without manual sorting.
This means building:
- Complexity detection algorithms that identify annotations handling unusual cases
- Comparative analysis that highlights work demonstrating sophistication beyond peers
- Model performance correlation that finds which annotators' work consistently improves capabilities
- Domain expert validation for work that automated systems flag as potentially exceptional
The goal is to develop a talent pool in which the best annotators handle the most critical work, rather than randomly distributing them across all tasks.
What this means for AI trainers
If you're working on AI training platforms, understand this: the infrastructure determines your ceiling.
Platforms built around quality averages will compensate you for volume and consistency. You're rewarded for being reliably mediocre. There's no path to differentiate yourself through expertise because the system doesn't measure or value expertise development.
Platforms built around quality variance create different economics. Your compensation reflects the value of your work in improving models, not just task completion. You have an incentive to develop deep expertise in specific domains because sophisticated capabilities are what frontier models need most.
The future of AI training work looks more like specialized expertise than standardized execution. The infrastructure you work on determines whether you're building skills that become more valuable as AI advances or executing tasks that become easier to automate.
6. Design systems that teach, not just execute
The worst infrastructure treats annotators as execution layers — give them tasks, collect outputs, move to the next batch. This works if tasks are simple and static. It fails as AI training evolves because you can't maintain quality when your workforce isn't learning.
The improvement engine
Quality infrastructure should make annotators better at their work over time, not just faster. This requires feedback loops that actually develop judgment:
When someone evaluates AI-generated code, they should see examples of evaluations that led to model improvements versus those that didn't. When they assess medical reasoning, they should get feedback from domain experts on what they missed. When they label edge cases, they should understand how their choices affect model behavior.
This isn't hand-holding. It's building expertise systematically. The annotators who understand what makes quality work valuable are the ones who can consistently produce it.
The incentive architecture
Your infrastructure encodes incentives through what it measures and rewards. If you measure speed, you get fast work. If you measure volume, you get high throughput. If you measure quality improvement over time, you get skill development.
Most platforms optimize for the wrong thing: consistent execution of current standards. This creates a workforce that's good at today's tasks but unprepared for tomorrow's complexity.
Better infrastructure rewards:
- Demonstrated improvement in handling complex edge cases
- Consistency in producing work that improves model capabilities
- Skill development in areas where models currently struggle
- Quality maintenance as task difficulty increases
This isn't altruism; it's recognizing that AGI development requires a workforce that gets more capable over time, not one that executes static processes efficiently.
What this means for AI trainers
The infrastructure you work on determines whether your skills compound or commoditize.
Platforms built around execution give you clear instructions, measure your compliance, and pay you for completing tasks. Your skills don't improve much because the system doesn't teach you what quality actually means. You're replaceable because you're doing what anyone with the exact instructions could do.
Platforms built around development show you what excellent work looks like, explain why it's excellent, and help you develop judgment that produces it consistently. Your skills compound because you're learning what actually matters in AI training. You become harder to replace because you've developed expertise that takes time to build.
As AI capabilities advance, the gap between these approaches widens. Commodity platforms automate away the work they're training you to do. Development platforms create more sophisticated work that requires the expertise you're building.
Choose accordingly.
Contribute to AGI development at DataAnnotation
The companies contributing most to AGI development aren't the ones processing the most annotations. They're the ones whose infrastructure enables quality measurement, skill differentiation, and continuous improvement at scale. They're building systems where both models and workers get better over time, not just faster.
That's the infrastructure that actually matters. Everything else is just moving data around more efficiently while hoping it's useful.
If your background includes technical expertise, domain knowledge, or the critical thinking to evaluate complex trade-offs, AI training at DataAnnotation positions you at the frontier of AGI development.
Over 100,000 remote workers have contributed to this infrastructure.
If you want in, getting from interested to earning takes five straightforward steps:
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking skills
- Check your inbox for the approval decision (typically within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. You can only take the Starter Assessment once, so read the instructions carefully and review before submitting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI — and you have the expertise to contribute.

Jennifer is a marketing professional who began her career with an internship in Hong Kong, where she produced online content articles analyzing marketing event performance. In 2020, she graduated from the University of South Florida with a BA in Marketing, gaining valuable experience in career-specific procedures and systems. Jennifer brings her marketing expertise and analytical skills to the DataAnnotation team.

Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.