


In this article
What did you find on job boards today? Another $6-per-hour microtask listing promising "flexible AI work from home." Yet you're wondering why premium platforms $20+ to $50+ per hour for AI training, while other platforms barely cover coffee money.
Most platforms treat AI training as commodity microtasks (click buttons, label images, transcribe audio) and pay accordingly.
We do ours differently.
We pay professional rates because we measure something fundamentally different: judgment quality, which determines whether billion-dollar training runs produce models that reason correctly or optimize for the wrong objectives.
This guide breaks down what separates commodity microtasks from expert-level AI training work: the capabilities premium platforms test, how to demonstrate judgment rather than just complete tasks, and why this work represents infrastructure for AGI development.
1. Understand why AI training pays more than crowdwork
Some microtask platforms advertise "AI training work" at $6 per hour. Premium platforms advertise similar-sounding work at 3x rates or more. The pay gap reflects a fundamental difference in what's being measured and valued.
Why task completion metrics create commodity wages
Crowdwork platforms measure task completion: clicked a checkbox, labeled an image, transcribed an audio segment. This binary measurement (task done or not) creates a commodity dynamic in which anyone who can follow basic instructions competes for the same work.
When the only measurable output is completion speed, platforms optimize for volume, and price falls toward whoever accepts the lowest rate.
Premium AI training platforms paying professional rates measure judgment quality:
- Does your feedback teach models correct reasoning patterns or just surface-level associations?
- Can you identify when AI responses look convincing but mislead through omission?
- Can you spot edge cases where guidelines break down and explain your reasoning process clearly?
These capabilities determine whether frontier model training succeeds or fails, thereby creating entirely different economic outcomes.
The quality ceiling determines your earning potential
Consider the quality ceiling concept. Drawing bounding boxes around cars in images has a low quality ceiling — you, a professional annotator, and a reasonably capable teenager will all produce roughly equivalent bounding boxes.
There's minimal room for expertise to add value, so pay reflects task completion rather than judgment sophistication. As models improved at image recognition, this work became increasingly automated, driving rates even lower.
Evaluating whether AI-generated reasoning demonstrates sound logic versus plausible-sounding nonsense has an unlimited quality ceiling. As models become more sophisticated, this evaluation work gets harder, not easier.
You're not checking whether the AI followed a template—you're assessing whether its reasoning would hold up under scrutiny, whether its analogies actually support its claims, and whether its conclusions follow from its premises.
This requires genuine intellectual engagement that becomes increasingly valuable as models improve, as the gap between "passing automated checks" and "actually advancing capabilities" widens.
What measurement infrastructure means for your compensation
The practical implication: if a platform can't explain how it measures quality beyond "we verify your credentials and trust you'll do good work," it likely operates on crowdwork economics regardless of what it calls itself.
Premium rates require measurement infrastructure that most platforms simply don't have.
When platforms can only track "task completed: yes/no," they force workers to compete on price regardless of expertise.
When platforms build measurement infrastructure that verifies specific workers improve model performance through better feedback, they can pay professional rates per hour because they prove ROI to AI companies training frontier models like Claude, GPT, and Gemini.
2. Choose platforms with quality measurement (not just resume verification)
Most platforms advertising AI training work follow the commodity approach: verify credentials at signup, provide task access, hope workers produce quality output, compete on price and pay peanuts to workers, because they can't prove their data improves model performance better than cheaper alternatives.
How commodity platforms hide behind credential verification
Without a way to measure output quality, platforms default to the lowest-cost labor and hope volume compensates for inconsistency. This creates the $6 per hour dynamic. Workers compete primarily on willingness to accept low rates rather than on expertise or judgment quality.

What real quality measurement looks like in practice
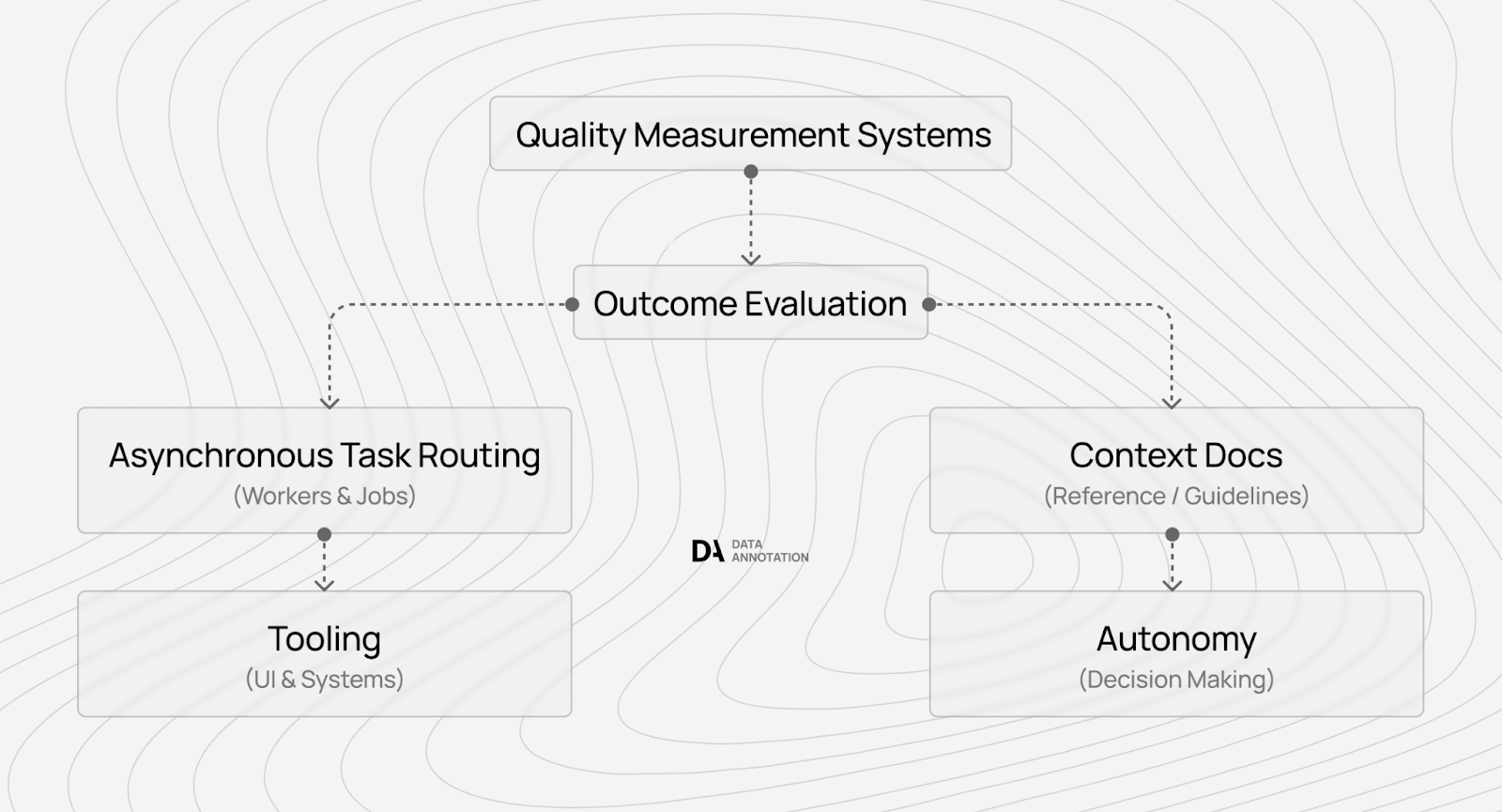
Premium platforms have built measurement infrastructure that fundamentally changes this dynamic. Think about what measurement enables.
When a platform can track that certain workers demonstrate systematic reasoning rather than case-by-case intuition, or spend appropriate time on complex evaluations without rushing through for volume, they can price these workers at premium rates because this feedback shows customers that it reduces the cost of expensive training failures.
At DataAnnotation, we pioneer this premium approach with tiered compensation: $25–$30+/hr for generalist work, up to $50-75+/hr for coding, and $50–$100+/hr for domain experts in STEM, law, finance, or medicine. These rates show that human judgment actually improves model performance rather than merely increasing annotation volume.
This isn't credential-based pricing where your resume determines your rate. It's performance-based pricing where demonstrated capability determines access to higher-compensation projects.
Questions that expose platforms without real infrastructure
Before applying to platforms, verify they have actual quality measurement through specific questions:
- How do they assess work quality beyond initial credential checks?
- What feedback mechanisms exist for improving performance over time?
- How do tier advancements work — time-based or performance-based?
- Can they explain how they prove value to customers training frontier models?
Legitimate answers involve technology, measurement systems, and verification processes. Vague responses about "experienced team review" or "industry standard practices" signal body shop approaches that struggle to support premium rates.
Universal red flags still apply regardless of advertised rates:
- Upfront access fees
- Crypto-only payments
- NDAs before rate disclosure
- No public review history
But for AI training work specifically, the more complex problem is distinguishing legitimate platforms that lack quality measurement from those with technology that enables and justifies premium compensation.
3. Build demonstrated capabilities (credentials don't predict performance)
Most job-hunting guides emphasize building credentials: earn certifications, complete online courses, and list degrees prominently. This advice wastes time for quality AI training work because credentials correlate poorly with the judgment quality that premium platforms actually measure.
Why credentials fail to predict AI training performance
Consider a pattern that holds across domains. Most computer science PhDs we’ve seen write code that's technically correct but practically problematic because their training emphasized theoretical elegance over production engineering.
They understand algorithmic complexity but miss pragmatic considerations such as maintainability, testing strategies, and how code integrates with existing systems. Similarly, many English PhDs we’ve seen struggle with creative writing despite deep literary knowledge.
This disconnect between credentials and capability persists throughout AI training. For instance, a chemistry PhD might excel at verifying molecular formulas but struggle to explain why an AI's reasoning about chemical reactions feels off despite technical accuracy.
A lawyer with decades of practice might spot contextual inappropriateness in AI-generated legal analysis that technically correct credentials alone wouldn't catch.
What premium platforms test for
Premium platforms like DataAnnotation test what actually matters:
- Can you identify when AI responses drift in tone mid-paragraph without someone pointing it out?
- Can you spot logical gaps in reasoning chains without peer discussion?
- Can you maintain consistency across large datasets without manager spot-checks?
- Can you articulate why one response demonstrates genuine insight while another just sounds sophisticated?
DataAnnotation's assessment structure reflects this focus on demonstrated capability over credentials.
The Starter Assessments test writing precision that identifies subtle communication issues, critical reasoning that evaluates argument quality, systematic attention that maintains consistency without supervision, and principled judgment that applies guidelines to novel cases they don't explicitly cover.
These capabilities determine success in actual AI training work more than what appears on your resume.
How to practice judgment quality instead of credential accumulation
Building these capabilities requires a different practice than credential accumulation.
The goal isn't an overnight transformation from generalist to expert, but rather to demonstrate that your existing knowledge enables quality judgments that credential-focused workers can't make and that automated systems can't verify.
This distinction determines whether you access premium-rate projects or compete in commodity microtask markets.
4. Pass assessments that measure quality and judgment (not volume)
Most qualification tests measure knowledge recall: do you know syntax rules, can you identify correct answers from multiple choices, can you complete tasks according to templates?
AI training assessments from premium platforms measure fundamentally different capabilities: judgment under ambiguity, reasoning transparency, and systematic thinking under conditions that mirror actual production work.
What AI training assessments measure versus knowledge tests
At DataAnnotation, our assessments primarily test whether you can apply principles to situations that guidelines don't explicitly cover. Speed doesn't come first because we measure quality, not velocity.
What matters is whether you can identify when cases require deeper analysis, articulate your reasoning process clearly enough for asynchronous review, extrapolate from stated principles to handle novel situations, and maintain consistent reasoning across varied scenarios.
Assessment structure and what each track evaluates
We offer track-specific Starter Assessments matching expertise levels:
- General assessments test writing clarity, critical thinking, and attention to detail for $20-$25+ per hour work.
- Coding assessments evaluate programming knowledge and code review capability for $50-$75+ projects.
- STEM assessments in math, chemistry, biology, or physics measure domain expertise for $40+ work.
- Professional assessments in law, finance, or medicine test specialized knowledge for $50+ opportunities.
- Language-specific assessments evaluate fluency for multilingual projects at $20+ per hour.
Most assessments require 60 to 90 minutes to complete thoughtfully, with specialized tracks potentially taking 2 hours due to complexity. This duration isn't arbitrary — it tests whether you can maintain focus and quality during the sustained work periods that actual projects require.
Preparation strategy: demonstrating reasoning over memorization
The critical preparation distinction:
- Don't optimize for finishing quickly, don't try to match imagined "correct answers,"
- Don't demonstrate breadth of knowledge for its own sake
Instead, optimize for articulating reasoning processes clearly, identifying when cases require deeper analysis rather than quick judgment, demonstrating systematic thinking that handles novel situations consistently, and engaging with underlying principles rather than surface rules.
Consider the difference between checkbox compliance and principled judgment.
When assessment guidelines say "prefer responses with factual accuracy," the checkbox approach rates AI outputs highly if they cite sources, regardless of whether citations support claims.
The judgment approach recognizes when citations serve as credibility theater rather than actual verification — and articulates why this matters: "Citations present but don't support claims, which is worse than no citations because it creates false confidence."
This reasoning demonstrates understanding of why guidelines exist rather than just that they should be followed. Preparation matters because you're showing how you actually think through complex problems, not proving you can memorize correct responses.
Explore AI training projects at DataAnnotation
Most platforms offer AI training as gig work, where you earn side income by clicking through microtasks. At DataAnnotation, we‘re at the forefront of AGI development, where your judgment determines whether billion-dollar training runs advance capabilities or optimize for the wrong objectives.
The difference matters. When you evaluate AI-generated code, your preference judgments influence how models balance helpfulness against truthfulness, how they handle ambiguous requests, and whether they develop reasoning capabilities that generalize or just memorize patterns.
This work shapes systems that millions of people will interact with.
If you want in, getting started is straightforward:
- Visit the DataAnnotation application page and click “Apply”
- Fill out the brief form with your background and availability
- Complete the Starter Assessment
- Check your inbox for the approval decision (which should arrive within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. Just remember: you can only take the Starter Assessment once, so prepare thoroughly before starting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI — and you have the expertise to contribute.

Phoebe is a California native currently based in Vermont. When she's not working, she enjoys traveling, playing drums, writing songs, and exploring the outdoors. With a background in public health and clinical research, Phoebe built a successful career in project management across both public and private sectors before joining DataAnnotation. She's excited to contribute to the platform's growth and its role in shaping the future of AI.
Related posts


Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.