


In this article
Every AI system that impressed you required thousands of hours of human judgment first. ChatGPT doesn't inherently know which responses are helpful. Tesla's self-driving system doesn't automatically recognize pedestrians. Claude doesn't naturally distinguish between an accurate answer and a confidently wrong one.
Humans taught them. And those humans got paid.
That exactly spells out data annotation.
You teach models what "correct" looks like by rating outputs, tagging content, and catching errors that automated systems miss. The work isn’t mindless clicking; it requires exceptional expertise, which is why it commands professional rates rather than typical gig wages.
This guide breaks down exactly what data annotation involves: seven annotation types with the skills each requires, how compensation scales with expertise, and the practical path from application to earning.
No vague promises about "shaping AI's future." Just the operational reality of remote work that fits around your life if you have the expertise.
What is data annotation?
Data annotation is the process of adding structured labels, ratings, and corrections to raw data so AI systems can learn from it. You're the teacher grading AI homework: when a chatbot generates a response, someone judges whether it's helpful or harmful. When an autonomous vehicle processes camera footage, someone outlines where the pedestrians actually are.
That someone gets paid because this judgment requires expertise that automation can't replicate.
The work spans every data type AI systems process: text, images, video, audio, code, and specialized scientific formats. Your annotations become the training signal that shapes how models behave.
When you mark a response as "helpful but contains a factual error," the model learns to prioritize accuracy. When you draw precise boundaries around a tumor in a radiology scan, diagnostic AI learns to detect cancer earlier.
Real-world applications
Every breakthrough AI system you've encountered required human annotation work first:
- Chatbot response rating: You evaluate whether AI-generated answers are helpful, accurate, or potentially harmful. When ChatGPT gives medical advice that sounds reasonable but could harm patients, someone needs to catch it. That evaluation directly shapes how tools like ChatGPT and Claude respond to millions of users.
- Autonomous vehicle training: You draw bounding boxes around pedestrians, cyclists, and road hazards in camera footage and LiDAR point clouds. A two-pixel error in pedestrian boundaries could cause a self-driving system to fail to brake in time. The precision requirements explain why this work demands sustained focus rather than fast clicking.
- Voice assistant development: You identify different speakers in audio recordings, transcribe speech with regional accents, and label conversational intent. When someone says, "play something relaxing," you're teaching Alexa whether that means music, a podcast, or ambient sounds.
- Code generation safety: You review AI-written code from tools like GitHub Copilot, flagging security vulnerabilities, logical errors, and violations of best practices before they reach developers. A missed SQL injection vulnerability in training data means the model learns to generate exploitable code.
- Medical image analysis: You trace tumor boundaries in radiology scans, distinguish benign masses from malignant ones, and identify anatomical structures. This work trains a diagnostic AI that assists healthcare professionals in early detection. The stakes demand domain expertise, not pattern recognition from guidelines.
- Financial compliance annotation: You analyze regulatory documents and flag compliance risks in contracts, teaching AI systems to identify potential legal issues. Understanding GAAP or IFRS standards means you catch problems that generalist annotators miss entirely.
Each application creates specialized tracks where your exceptional expertise translates directly into remote income. The technical complexity means this work demands real expertise. That's why it commands professional rates.
Types of data annotation work and the skills you need
Your expertise determines your earning potential. Data annotation spans multiple formats and techniques, each requiring different skills and offering different compensation.
Data annotation spans multiple formats and techniques, each requiring different skills and offering different compensation levels. Your expertise determines your earning potential. Plus, different specializations command different rates based on complexity and the background knowledge required.
At DataAnnotation, generalist work starts at $25–$30+/hr, coding work earns up to $50-75+/hr, and domain experts in law, finance, medicine, or STEM earn $50–$100+/hr.
"Right now, as a coder on Data Annotation, I am earning over $6,000 a month on part-time hours. DataAnnotation has allowed me to pay off all my debts and own my own house at 27. In all seriousness, Data Annotation is the best online platform to earn money as a coder."
Text annotation
Text annotation trains language models to understand human communication. You evaluate AI-generated responses, identify entities in sentences (distinguishing "Apple" the company from "apple" the fruit), analyze sentiment in customer reviews, and rank different versions of AI outputs.
The work looks like this: You receive three AI-generated email responses to a customer complaint. You score each for tone (professional vs. defensive), accuracy (does it address the actual issue?), and helpfulness (would this resolve the problem?). Your rankings serve as a training signal indicating which response style the model should prefer.
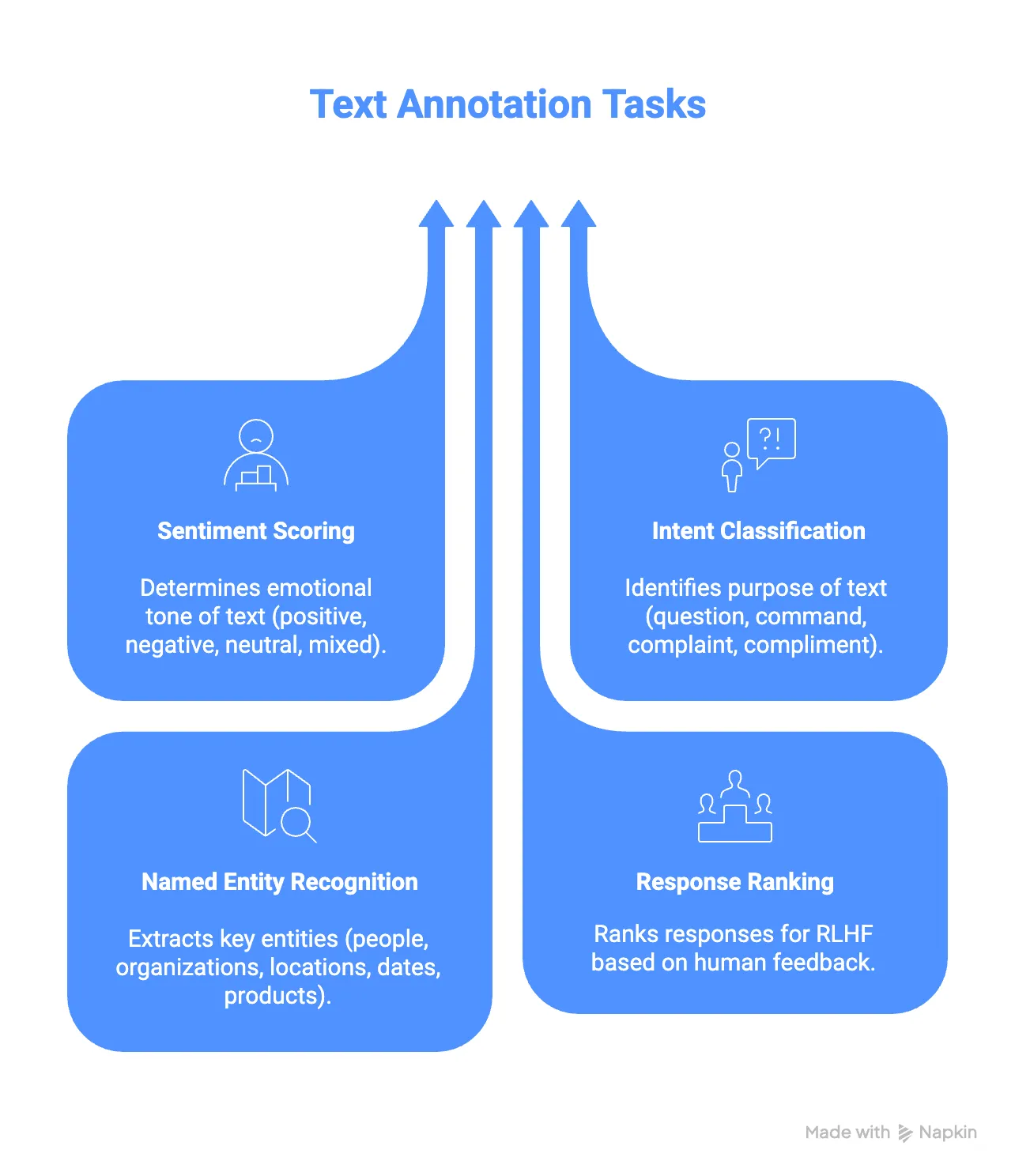
Typical tasks include:
- Sentiment scoring (positive, unfavorable, neutral, mixed)
- Intent classification (question, command, complaint, compliment)
- Named entity recognition (people, organizations, locations, dates, products)
- Response ranking for reinforcement learning from human feedback (RLHF)
You work from detailed guidelines that define edge cases and provide examples, then apply consistent judgment across hundreds of samples. When the guidelines say "mark sarcasm as negative sentiment," you follow that rule even when you personally find the sarcasm funny.
Skills needed: Native-level language proficiency, attention to detail, ability to follow complex guidelines consistently, and critical reading comprehension. If you catch yourself mentally editing news headlines or spotting bias in marketing copy, you have the instincts this work requires.
Image and video annotation
Computer vision systems need human-labeled training data to interpret visual information. You’ll draw bounding boxes around objects, trace precise boundaries for semantic segmentation, and track items across video frames: work that teaches autonomous vehicles and medical imaging tools to “see” correctly.
The workflow varies by project complexity:
- Simple object detection means drawing rectangles around cars in traffic camera footage
- Semantic segmentation requires pixel-level precision, tracing tumor boundaries in CT scans or outlining individual plants in agricultural drone imagery
- Instance segmentation combines both, labeling each separate person in a crowded scene.
Video annotation adds temporal complexity. You might track a cyclist through 100 frames of dash-cam footage, maintaining consistent labels as lighting changes and occlusion occur. Sports analytics projects require you to classify player actions frame by frame. Retail projects track customer movements through stores.
However, visual acuity matters more than speed here. A two-pixel error in a medical image boundary can confuse diagnostic models. Meanwhile, inconsistent object tracking ruins autonomous vehicle training data.
The work demands sustained focus and spatial reasoning ability, not just fast clicking.
Required skills: strong visual acuity, spatial reasoning, consistency across long sessions, basic understanding of how computer vision models use labeled data. If you naturally notice misaligned elements in design or can maintain focus during detail-intensive tasks, this specialization might fit.
Audio annotation
Voice-enabled AI systems need annotators who can transcribe speech, identify different speakers, label background noise, and tag conversational intent. You’re teaching smart speakers, call center bots, and voice assistants to understand human audio in all its messy reality.
The work combines listening stamina with linguistic precision:
- Speech-to-text transcription requires you to capture every word accurately, including hesitations, false starts, and regional accents.
- Speaker diarization means labeling who’s speaking when in multi-person conversations, which is crucial for meeting transcription tools.
- Intent tagging classifies what people actually want when they give voice commands, such as“play music,” “play news,” or “play my voicemail.”
- Background noise labeling means marking dog barks, traffic sounds, TV audio bleeding into phone calls, and anything else that shouldn’t influence the model’s interpretation of speech.
Multilingual speakers have premium opportunities here. Global companies need annotators for low-resource languages (regional dialects, minority languages, specialized vocabulary) where automated systems fail.
Skills needed: sharp auditory discrimination, native or near-native language proficiency, ability to distinguish similar sounds, stamina for extended listening sessions. If you naturally catch misheard lyrics or can identify speakers by voice alone, you have relevant instincts.
Coding annotation
AI code generation tools need developers who can evaluate their output. You’ll review AI-generated code snippets, identify bugs, suggest fixes, rate code quality, and flag security issues. This work trains systems like GitHub Copilot to write safer, more maintainable code.
The workflow mirrors standard code review.
Example projects include:
- Receiving a function that’s syntactically correct but logically flawed and having to explain why the edge case fails
- Comparing three different implementations of the same algorithm and ranking them by efficiency, readability, and best practices
- Spotting injection vulnerabilities, hardcoded credentials, or improper error handling for security review
Your debugging instincts and language-specific knowledge make the difference between helpful and harmful AI assistance. When an AI generates code that technically works but violates framework conventions or introduces subtle race conditions, you catch it.
When it produces clever-looking code with performance implications, you explain the tradeoff.
Projects can span multiple programming languages: Python, JavaScript, TypeScript, C, C++, C#, Java, Kotlin, Swift, and more. Domain knowledge matters. For instance, web development expertise helps you evaluate frontend frameworks. A systems programming background improves your hardware-level code reviews.
Skills needed: professional programming experience, debugging ability, understanding of code quality principles, and security awareness. If you regularly spot issues in pull requests or mentally refactor poorly written code, you have the critical eye this work requires.
Specialized STEM and domain-specific annotation
Some datasets are so technical that only domain experts can label them safely. Medical images, genomic sequences, chemistry diagrams, and physics simulations all require annotators who understand the underlying science, not just visual patterns.
What domain-specific work involves:
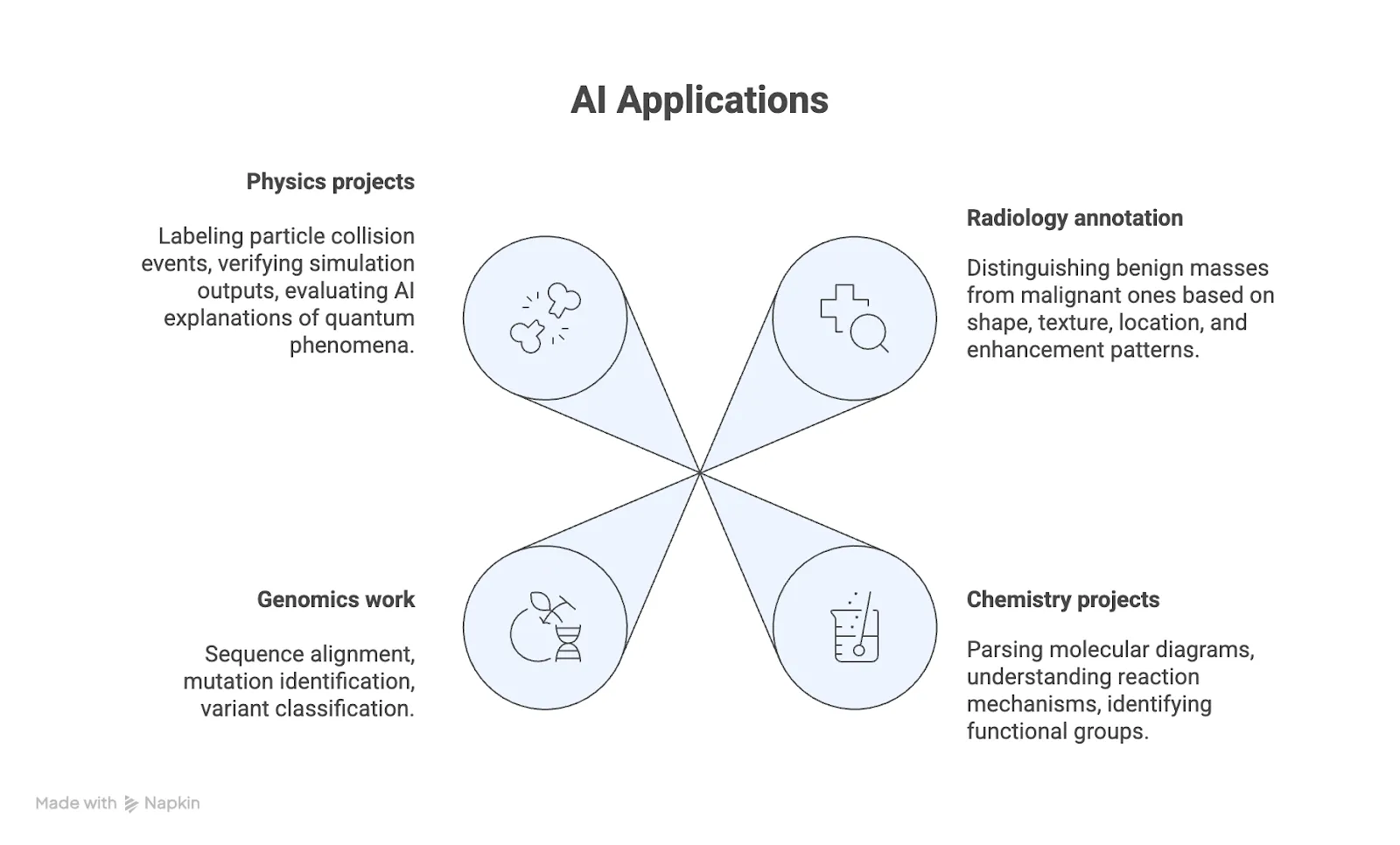
- Radiology annotation: Distinguishing benign masses from malignant ones based on shape, texture, location, and enhancement patterns
- Chemistry projects: Parsing molecular diagrams, understanding reaction mechanisms, and identifying functional groups
- Genomics work: Sequence alignment, mutation identification, variant classification
- Physics projects: Labeling particle collision events, verifying simulation outputs, evaluating AI explanations of quantum phenomena
The workflow often includes consulting specialized ontologies (standardized vocabularies for your field) and escalating edge cases to colleagues with more profound subspecialty knowledge. You're not making diagnostic decisions; you're providing ground truth that trains AI systems to recognize patterns in your domain.
This work demands rigorous accuracy because errors have real-world consequences. A mislabeled tumor in training data could lead to missed diagnoses. Incorrect molecular structure annotations could compromise drug discovery research. Misclassified genomic variants could affect treatment decisions.
Skills needed: Advanced degree (typically master's or PhD) or equivalent professional experience in the relevant domain, ability to work with specialized terminology and ontologies, understanding of how domain-specific data trains AI models.
If you've published research, hold professional certifications, or spent years applying scientific knowledge in practice, this tier compensates your expertise appropriately.
LiDAR annotation
Autonomous vehicles and robotics systems navigate using LiDAR sensors that generate 3D point clouds, made up of millions of data points representing distances to surrounding objects. Your job is to make sense of what looks like noisy constellations and label vehicles, pedestrians, cyclists, and infrastructure with millimeter-level precision.
The work requires strong spatial reasoning. You’ll draw 3D bounding boxes around objects in point cloud data, tracking them across frames as they move. A cyclist turning creates a point cloud shape that you need to anticipate.
Parked cars partially hidden behind trees require you to infer complete boundaries from incomplete data.
Understanding basic physics helps you answer questions like:
- How does a pedestrian’s point cloud change as they walk toward the sensor?
- What distinguishes a motorcycle from a bicycle in 3D space?
- Why do glass surfaces and rain create point cloud artifacts?
This intuition improves label quality and speeds your work.
Skills needed: spatial reasoning, comfort with 3D visualization tools, basic physics understanding, attention to millimeter-scale detail, consistency across thousands of frames. If you naturally understand 3D space, can mentally rotate objects, or have experience with CAD or 3D modeling tools, you’re likely well-suited for this work.
Who qualifies for AI training work at DataAnnotation?
At DataAnnotation, AI training isn't mindless data entry. It's not a side hustle. We believe it's the bottleneck to AGI.
Every frontier model (the systems powering ChatGPT, Claude, Gemini, etc.) depends on human intelligence that algorithms cannot replicate. As models become more capable, this dependence intensifies rather than diminishes.
The data annotation market is projected to grow at 26% annually through 2030, driven by expanding AI capabilities that require increasingly sophisticated training data. But growth obscures a fundamental split in the industry: body shops scaling commodity labor versus technology platforms scaling expertise.
If you have genuine expertise (coding ability, STEM knowledge, professional credentials, or exceptional critical thinking), you can help build the most important technology of our time at DataAnnotation.
Our quality AI training work is for:
Domain experts who want their expertise to matter: For instance, computational chemists who are tired of pharmaceutical roles where their knowledge gets underutilized. Mathematicians seeking intellectual engagement beyond teaching introductory calculus. Programmers who want to apply their craft to advancing AI rather than debugging legacy enterprise software.
Professionals who need flexible income without sacrificing intellectual standards: For example, the researcher awaiting grant funding who can contribute to frontier model training while maintaining their primary focus. The attorney with reduced hours who can apply legal reasoning to AI safety problems. The STEM professional who needs work without geographic constraints.
Creative professionals who understand craft: Examples include writers who can distinguish between generic AI prose and genuinely compelling narratives. Poets who recognize that technique without creativity produces mediocre work, regardless of formal training.
People who care about contributing to AGI development: Workers who understand that training frontier models matters more than optimizing their personal hourly rate. Experts recognize that their knowledge becomes exponentially more valuable when transferred to AI systems that operate at scale.
The poetry you write serves as a model for creativity and language. The code you evaluate helps them learn software engineering judgment. The scientific reasoning you demonstrate advances their capability to assist with research.
How to get an AI training job?
At DataAnnotation, we operate through a tiered qualification system that validates expertise, including completed or in-progress bachelor’s degree experience where relevant, and rewards demonstrated performance.
Entry starts with a Starter Assessment that typically takes about an hour to complete. This isn't a resume screen or a credential check — it's a performance-based evaluation that assesses whether you can do the work.
Pass it, and you enter a compensation structure that recognizes different levels of expertise:
- General projects: $25–$30+/hr for evaluating chatbot responses, comparing AI outputs, and writing challenging prompts, typically requiring a completed or in-progress bachelor’s degree or equivalent experience
- Multilingual projects: $20–$50+/hr for translation and localization work across many languages
- Coding projects: Earn up to $50-75+/hr for code evaluation and AI performance assessment across Python, JavaScript, HTML, C++, C#, SQL, and other languages
- STEM projects: $50–$100+/hr for domain-specific work requiring a completed or in-progress bachelor’s degree through PhD-level knowledge in mathematics, physics, biology, and chemistry
- Professional projects: $50–$100+/hr for specialized work requiring credentials in law, finance, or medicine
Once qualified, you select projects from a dashboard showing available work that matches your expertise level. Project descriptions outline requirements, expected time commitment, and specific deliverables.
You can choose your work hours. You can work daily, weekly, or whenever projects fit your schedule. There are no minimum hour requirements, no mandatory login schedules, and no penalties for taking time away when other priorities demand attention.
The work here at DataAnnotation fits your life rather than controlling it.
Explore AI training work at DataAnnotation today
The gap between models that pass benchmarks and those that work in production lies in the quality of the training data. If your background includes technical expertise, domain knowledge, or the critical thinking to spot what automated systems miss, AI training at DataAnnotation positions you at the frontier of AI development.
Not as a button-clicker earning side income, but as someone whose judgment determines whether billion-dollar training runs advance capabilities or learn to optimize the wrong objectives.
Getting from interested to earning takes five straightforward steps:
- Visit the DataAnnotation application page and click “Apply”
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking and attention to detail
- Check your inbox for the approval decision (which should arrive within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. Just remember: you can only take the Starter Assessment once, so prepare thoroughly before starting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI — and you have the expertise to contribute.

Jennifer is a marketing professional who began her career with an internship in Hong Kong, where she produced online content articles analyzing marketing event performance. In 2020, she graduated from the University of South Florida with a BA in Marketing, gaining valuable experience in career-specific procedures and systems. Jennifer brings her marketing expertise and analytical skills to the DataAnnotation team.
Related posts



Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.