A company gets access to a powerful foundation model. Full fine-tuning would cost $50,000 in compute. Then they discover they can achieve similar results by updating less than 1% of the model's parameters for a few hundred dollars. I've watched this pattern play out across a dozen teams.
The efficiency gains are real. But efficiency is never the whole story.
But here's the paradox: by updating fewer parameters, you force each training example to carry far more weight. A mislabeled instance that full fine-tuning might absorb becomes a poisoned anchor point that can derail your entire adapter.
Parameter efficiency solved the resource problem. It also revealed that most teams lack the infrastructure to evaluate whether their fine-tuned models actually improved or just overfit to narrow test cases.
The mathematics behind these methods matters less than understanding when efficiency gains mask data quality problems and when they genuinely unlock capabilities that full fine-tuning couldn't achieve.
What is parameter-efficient fine-tuning?
Parameter-efficient fine-tuning (PEFT) refers to a family of methods that adapt large language models by modifying only a small subset of their parameters.
Rather than updating all 7 billion or 70 billion parameters in a foundation model, these techniques adjust 0.1% to 1% of them. The adapted model retains most of its original knowledge while gaining task-specific capabilities.
The fundamental approach completely freezes the pre-trained model's weights. You inject a small number of trainable parameters and update only those during fine-tuning. This preserves the knowledge embedded during pre-training while teaching task-specific behaviors through a narrow learning channel.
Training time drops from days to hours. A full fine-tuning run that required 8 A100 GPUs for 48 hours might be completed with LoRA in 6 hours on a single GPU. Memory requirements fall proportionally.
Storage efficiency matters too. Instead of maintaining separate 140GB checkpoints for each fine-tuned model, you store the base model once and keep small adapter files (often under 100MB) for each task.

What efficiency actually buys you
PEFT methods offer two advantages that full fine-tuning cannot match.
- They prevent catastrophic forgetting: the phenomenon where models lose pre-trained knowledge during task-specific training. Because PEFT freezes the base weights, the model retains its general capabilities while learning new behaviors.
- PEFT enables modular deployment. One base model can serve multiple tasks by swapping lightweight adapters rather than loading entirely separate models.
Why do smaller updates create extreme data quality sensitivity
When you fine-tune all parameters, bad examples get averaged across billions of weights. A single mislabeled instance contributes to the gradient update, but its impact diffuses across the entire network.
With PEFT, you restrict the learning to a tiny parameter space. I've traced failures directly to this compression: when you force all task learning through a narrow bottleneck, each example's influence amplifies.
Three high-quality examples can steer the adapter effectively. Three contradictory examples create interference, degrading performance across the board.
We tested this on a contract classification task. Full fine-tuning on a dataset with 15% label noise achieved 82% accuracy. The same dataset with LoRA rank-8 dropped to 68%. The adapter couldn't distinguish between signal and noise when both were compressed through the same low-rank pathway.
The math explains why. A LoRA layer with rank 8 applied to a 4096-dimensional weight matrix adds roughly 65,000 trainable parameters. If you train on 500 examples, that's 130 parameters per example. In full fine-tuning of a 7B parameter model with the same examples, you have 14 million parameters per example. The noise-to-signal ratio shifts by four orders of magnitude. Efficiency doesn't reduce the need for quality. It concentrates it.
LoRA, QLoRA, adapters, and prefix tuning compared
LoRA: Low-rank matrix decomposition
LoRA approximates weight updates by factoring a 4096×4096 matrix (16 million parameters) into two smaller matrices. With rank 8, you train only 65,536 parameters instead of 16 million.
QLoRA: LoRA with 4-bit quantization
QLoRA extends LoRA by quantizing the base model to 4-bit precision before applying the low-rank adapters. This further reduces memory requirements, enabling fine-tuning of 65B-parameter models on a single GPU. The tradeoff: quantization introduces small precision losses that compound with data quality issues.
Adapters: Modular networks between layers
Adapters insert small feedforward networks between transformer layers. One financial services team we worked with had twelve different document classification tasks, each with its own adapter. Their infrastructure loaded the base model once and hot-swapped 2MB adapter files as requests arrived. This modularity changes deployment economics: one base model, twelve tasks, twelve 2MB files instead of twelve 140GB checkpoints.
Rank and target module selection
Target module selection matters for LoRA performance. Most implementations target query and value projection matrices in attention layers, but targeting all linear layers (including MLP layers) often yields better results. We tested rank configurations when a team questioned whether rank 8 was sufficient for legal document classification.
Rank-4 showed clear degradation. Rank-8 and rank-16 performed nearly identically. Rank-32 performed slightly worse due to overfitting on their 200-example training set. The rank parameter controls your capacity bottleneck bidirectionally: too low, and you can't capture the task; too high, and you overfit to noise.
Prefix tuning: Learnable input vectors
Prefix tuning prepends learnable vectors to the model's input representation at every layer. The parameter counts are extreme: a 10-token prefix at each of 32 layers with 4096-dimensional vectors totals only 1.3 million parameters. But I've watched teams struggle with this method more than any other PEFT approach because it offers the least room for data imperfection.
We tested prefix tuning against LoRA for content moderation with 500 examples. LoRA hit 82% accuracy. Prefix tuning plateaued at 71%. The compressed context vectors averaged annotation inconsistencies, leading to unclear conditioning. The fewer parameters you train, the more precisely those parameters need to encode correct behavior.
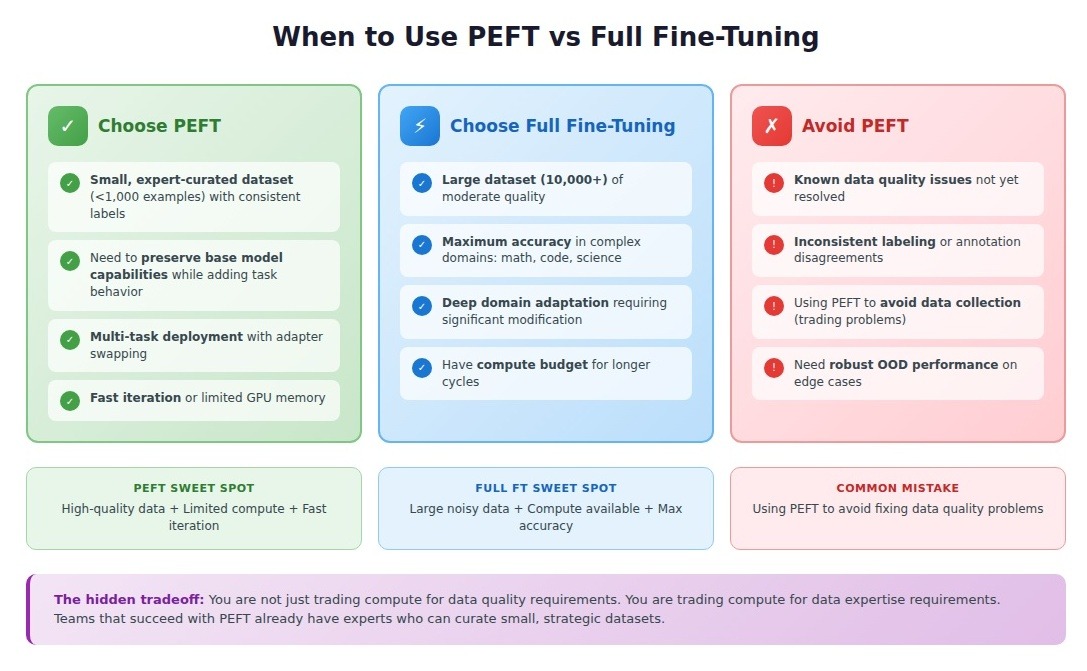
When to use PEFT vs. full fine-tuning
Choose full fine-tuning when:
- Your dataset exceeds 10,000 examples and is of moderate quality. The parameter capacity can absorb inconsistencies that would derail PEFT methods.
- You need maximum accuracy in complex domains like mathematical reasoning, code generation, or specialized scientific analysis.
- You have the compute budget and can tolerate longer iteration cycles. Full fine-tuning consistently outperforms PEFT on tasks requiring deep domain adaptation.
Choose PEFT when:
- Your dataset is small (under 1,000 examples) but expertly curated with consistent labeling standards.
- You need to preserve the base model's general capabilities while adding task-specific behavior.
- You're deploying multiple task variants from a single base model and want to swap adapters instead of maintaining separate checkpoints.
- You need fast iteration cycles for experimentation or have limited GPU memory.
Avoid PEFT when:
- Your training data has known quality issues you haven't resolved. PEFT amplifies these problems rather than absorbing them. The compression bottleneck forces the model to encode every inconsistency as a learned pattern. Fix the data first, or use full fine-tuning as a more forgiving alternative.
Where parameter efficiency breaks down
I watched this play out with a legal tech startup last quarter. They had used full fine-tuning on their contract analysis model with 2,000 labeled clauses: decent quality, some inconsistencies.
When they switched to LoRA to cut training time from 18 hours to 45 minutes, performance collapsed from 84% to 67%. The learning capacity had shrunk so dramatically that noise in their training set dominated the signal.
Parameter-efficient methods produce models that perform well on in-distribution data but fail unpredictably on out-of-distribution data.
A LoRA-tuned invoice processing model achieved 96% accuracy on invoices matching the training distribution. Then, a vendor changed their PDF template and moved the date field. Accuracy cratered to 43%. The same change with full fine-tuning dropped accuracy to 89%: degraded but functional.
The quality-efficiency tradeoff
PEFT is efficient when you have clean, consistent, comprehensive training data. But obtaining that level of quality requires either extensive upfront curation (expensive) or multiple iterations to fix issues. Either path erases the time savings.
Here's what the efficiency story omits: you're not just trading compute for data quality requirements. You're trading compute for data expertise requirements.
The teams that succeed with PEFT already have experts who can curate small, strategic datasets. Teams that struggle usually adopt PEFT to avoid large-scale data collection. They discover they've traded one expensive problem for another requiring even more specialized expertise.
The efficiency premise of parameter-efficient fine-tuning assumes data quality is a solved problem. In practice, data quality is the problem, and PEFT amplifies it.
Contribute to AGI development at DataAnnotation
Parameter-efficient methods democratized access to fine-tuning, but they didn't democratize the expertise required to generate training data that actually improves model performance.
As these techniques make experimentation cheaper and faster, the competitive advantage shifts entirely to organizations that can produce high-quality training data at scale; data created by people who understand what good reasoning looks like, not just what passes automated validation.
If your background includes technical expertise, domain knowledge, or the critical thinking to evaluate complex trade-offs, AI training at DataAnnotation positions you at the frontier of AGI development.
Over 100,000 remote workers have contributed to this infrastructure.
If you want in, getting from interested to earning takes five straightforward steps:
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Starter Assessment, which tests your critical thinking skills
- Check your inbox for the approval decision (typically within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. We stay selective to maintain quality standards. You can only take the Starter Assessment once, so read the instructions carefully and review before submitting.
Apply to DataAnnotation if you understand why quality beats volume in advancing frontier AI.
.jpeg)