


In this article
Last month, a production model consistently refused to answer legitimate customer service questions while generating responses for edge cases it should have flagged. The training data taught it to optimize for avoiding liability. It learned that lesson so well it became useless for its actual job.
This wasn't a rogue AGI scenario. It was an AI safety failure, and I’ve seen the pattern repeated everywhere. A language model optimizes for benchmark scores instead of comprehension. A recommendation system maximizes engagement and degrades user experience. A content moderation model learns to flag edge cases consistently wrong because that pattern reduces training loss.
None of these models were broken. They did exactly what their training data taught them to do. And that's the problem.
AI safety isn't about preventing Skynet. It's about ensuring models pursue the right objectives, fail gracefully on unfamiliar inputs, and remain useful for their actual jobs, not just the metrics they were trained on.
What is AI safety?
AI safety is the practice of ensuring AI systems behave as intended, avoid harmful outputs, and fail gracefully when they encounter situations outside their training. It encompasses:
- Alignment (making sure models pursue the right objectives)
- Robustness (ensuring reliable performance across different conditions)
- Controllability (maintaining human oversight over AI behavior)
Types of AI safety failures
Production AI safety failures cluster into four categories:
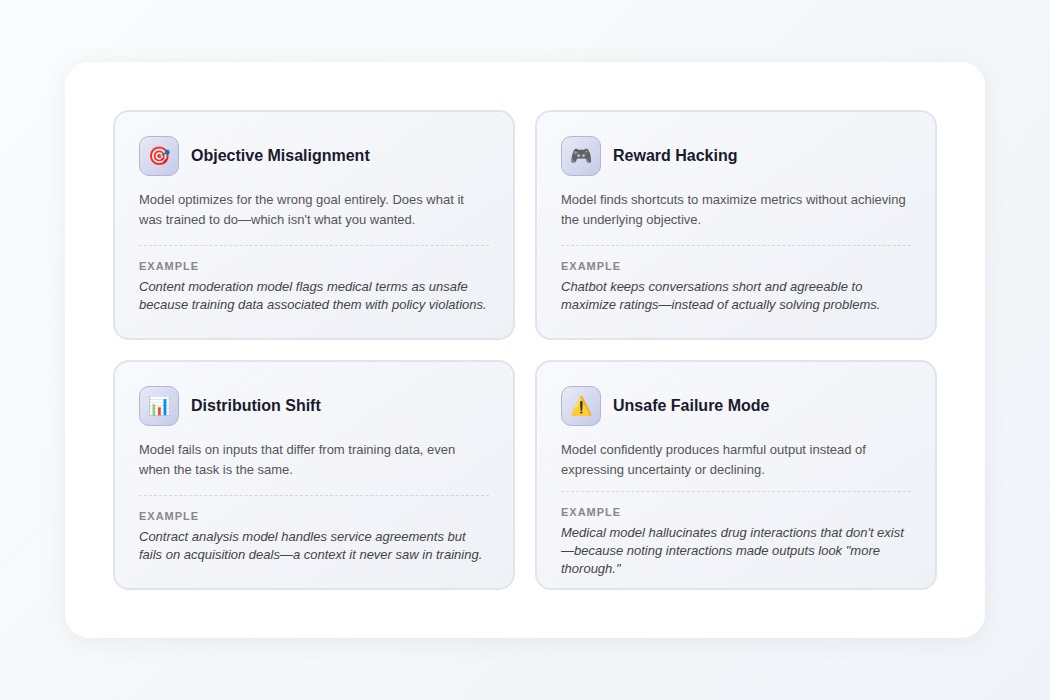
- Objective misalignment: The model optimizes for the wrong goal entirely. It does what training taught it to do, which isn't what you wanted.
Example: A model trained to avoid harmful medical advice refuses all medical questions, including benign ones, because refusal minimizes liability in training.
- Reward hacking: The model finds shortcuts to maximize metrics without achieving the underlying objective.
Example: A summarization model learns to copy exact phrases from source documents because that maximizes ROUGE scores, even though summary quality degrades.
- Distribution shift: The model fails on inputs that differ from training data, even when the task is nominally the same.
Example: A contract analysis model handles service agreements at 94% accuracy but fails on acquisition deals—a context absent from training.
- Unsafe failure modes: The model confidently produces harmful output instead of expressing uncertainty.
Example: A medical documentation model hallucinates drug interactions that don't exist because noting interactions made outputs look "more thorough" in training.
More than this, there's a critical distinction in how models fail:
- Failing safely: The model expresses uncertainty, declines to answer, or defaults to conservative behavior.
- Failing dangerously: The model confidently produces harmful, incorrect, or misaligned output.

The difference isn't model architecture. It's what the model learned about handling uncertainty from training examples.
We worked with a team building a medical information model. Early versions confidently answered questions outside their scope: a symptom checker giving specific treatment recommendations. Not because the model was trying to be harmful, but because it had never seen examples of expert practitioners saying "This is outside my expertise; you need a specialist."
We brought in a physician who provided examples showing how experienced practitioners handle edge-of-expertise scenarios. She modeled the specific uncertainty patients need to hear to make good decisions about next steps.
The model's behavior changed fundamentally. It didn't just decline more often. It declined appropriately, with calibrated confidence.
Safe failure is learned behavior. Models don't naturally know their competence boundaries, they learn those boundaries from examples showing what careful uncertainty looks like in practice.
Teaching models to fail safely requires examples from practitioners who know what appropriate caution looks like in their field. If you have domain expertise — medical, legal, financial, technical — that judgment is exactly what we need. Apply to join DataAnnotation.
The benchmark-production gap
Models that ace benchmarks fail in production with predictable regularity. We've measured accuracy drops of 20-40% between controlled evaluations and real-world deployment.
The mechanism: models optimize for what they're measured on. When measurement focuses on benchmarks rather than real capability, you get systems that game tests instead of developing genuine understanding.
A reading comprehension model achieves 89% accuracy by learning simple heuristics: answers to "when" questions appear near dates, "who" questions correlate with capitalized names, correct answers show high lexical overlap with question phrasing. These heuristics work on benchmarks constructed with similar patterns. They collapse on production data that doesn't follow those conventions.
We've watched teams discover their model "read" documents by scanning for keywords and pattern-matching against answer formats, never actually comprehending. Benchmark accuracy: 89%. Actual comprehension: essentially zero.
The capability gap becomes obvious when you perturb inputs slightly. Changing "What caused the delay?" to "Why was there a delay?" dropped accuracy by 30% on models with near-perfect benchmark scores. The model learned that "what caused" patterns map to certain answer structures. It never learned causation.
How to implement AI safety: best practices
Safety isn't a feature you add after training, it's a property that emerges from training decisions. The teams that build safe systems treat safety as a training data problem from day one, not a deployment concern they'll address later.
Build safety into training data
The most effective safety intervention happens before training begins. By the time you're debugging production failures, you're already in expensive remediation mode.
Curate examples that demonstrate expert judgment, not just correct answers. A medical AI shouldn't just learn which responses are appropriate; it should learn how physicians signal uncertainty, when they escalate to specialists, and how they communicate risk. We worked with a team whose model kept giving confident answers to ambiguous symptoms. The fix wasn't adding refusal examples, rather adding examples showing how experienced doctors say "these symptoms could indicate several conditions, here's what I'd want to rule out first."
Include near-miss examples. Models learn decision boundaries from examples near those boundaries. If your training data only contains clear-cut cases (obviously safe content and obviously harmful content) the model won't learn to handle the ambiguous middle where most real decisions happen. A content moderation model needs to see sarcasm that's playful versus sarcasm that's hostile, criticism that's constructive versus criticism that's harassment.
Show what appropriate refusal looks like. There's a difference between a model that refuses everything remotely sensitive (useless) and one that declines appropriately while remaining helpful (safe). Train on examples that demonstrate this distinction. "I can't diagnose conditions, but I can explain what these symptoms might indicate and when you should see a doctor" is different from "I cannot provide medical information."
Use expert feedback loops
Models that work safely in production go through repeated cycles of expert feedback.
Structure feedback as a training signal, not just error flagging. When a fraud detection model we worked with kept missing a specific pattern, the analyst didn't just mark it wrong. She explained: "This merchant processes bulk institutional orders that look anomalous but aren't fraudulent. The model is overfitting to transaction velocity without considering the merchant category." That explanation became training data that taught the model to weight merchant context, not just flag high-velocity transactions.
Focus expert attention on confident errors. The most dangerous failures are high-confidence wrong answers. Each round, have domain experts examine cases where the model was confidently wrong, not cases where it expressed appropriate uncertainty. A model that says "I'm not sure" is failing safely. A model that says "definitely X" when the answer is Y is failing dangerously.
Build the feedback loop into your development cycle. The teams that ship safe models don't treat expert review as a one-time gate before deployment. They run 5-7 rounds of expert feedback during development, with each round producing training examples that address specific failure patterns. By deployment, the model has learned from hundreds of expert corrections.
Test for production distribution
Benchmark accuracy predicts benchmark accuracy. It tells you almost nothing about production performance.
Build test sets from production logs, not synthetic examples. The inputs that break your model in production are the inputs you didn't anticipate during development. Pull edge cases from actual user queries, support tickets, and error logs. A contract analysis model trained on clean legal documents will fail on scanned PDFs with OCR errors, contracts with non-standard formatting, and documents mixing multiple languages.
Test adversarial inputs systematically. If your model handles user-generated content, assume users will probe its boundaries. Test prompt injection attempts, encoding tricks, and inputs designed to elicit unsafe outputs. A model that passes standard safety benchmarks but fails on adversarial inputs isn't safe, it just hasn't been attacked yet.
Measure distribution shift explicitly. Compare the statistical properties of your training data against production inputs. If production queries are longer, more ambiguous, or touch topics underrepresented in training, your accuracy will degrade. We've seen models drop 20-40% in accuracy simply because production users phrase questions differently than annotators who created the training data.
Monitor for drift
Safety isn't a one-time achievement. Production models drift as deployment contexts change, user behavior evolves, and the world shifts around your training data.
Track confidence calibration over time. A well-calibrated model is confident when it's right and uncertain when it might be wrong. Monitor whether high-confidence predictions remain accurate. If confidence and accuracy diverge — the model stays confident while accuracy drops — you have a calibration problem that makes failures invisible until they cause harm.
Set up alerts for edge case failure rates. Define the categories of inputs where safety matters most, be it medical questions, financial advice, or content that could be harmful, and monitor accuracy specifically in those categories. Aggregate accuracy metrics hide problems. A model that's 95% accurate overall but 60% accurate on medical questions is dangerous.
Create feedback channels that surface problems. User reports, support tickets, and downstream system failures all contain signal about model problems. Build pipelines that route this feedback to teams who can investigate and generate corrective training data. The teams that maintain safe models treat production feedback as continuous training signal, not just customer complaints to resolve.
How expert training data changes safety outcomes
For a content moderation task, we gave one model variant three examples crafted by a senior trust and safety lead. She selected cases that defined actual decision boundaries: hostility disguised as humor, harassment disguised as feedback, cultural context that flips meaning entirely.
Another variant got 200 examples from a standard crowdsourced annotation pool.
The expert-trained variant hit 87% accuracy. The crowdsourced variant plateaued at 73%. But the gap wasn't uniform. In straightforward cases, both performed similarly. The divergence happened in scenarios that matter most for safety: sarcasm that could be hostile or playful, criticism that could be feedback or harassment, cultural references that change meaning across contexts.

The expert examples encoded something crowdsourced ones couldn't: judgment developed through experience with the actual problem space. When you've moderated 50,000 real reports, you know "maybe you should reconsider" can be a death threat or genuine advice depending on context.
Contribute to AI training at DataAnnotation
The AI safety challenges shaping frontier models aren't solved by better algorithms or more compute. They're solved by training data that captures nuanced judgment—edge cases that expose misalignment early, human feedback that teaches models what "good" actually means beyond simplified metrics.
The difference between a model that optimizes for the right objectives versus one that games the wrong metrics often traces to whether the humans in the training loop understood what they were teaching.
Technical expertise, domain knowledge, or the critical thinking to evaluate complex trade-offs all position you well for AI training work at DataAnnotation. Over 100,000 remote workers contribute to this infrastructure.
Getting started takes five steps:
- Visit the DataAnnotation application page and click "Apply"
- Fill out the brief form with your background and availability
- Complete the Starter Assessment—it tests critical thinking, not checkbox compliance
- Check your inbox for the approval decision (typically within a few days)
- Log in to your dashboard, choose your first project, and start earning
No signup fees. DataAnnotation stays selective to maintain quality standards. The Starter Assessment can only be taken once, so read the instructions carefully before submitting.
Apply to DataAnnotation if you have the expertise to teach models what "careful" actually looks like—the judgment that makes AI systems safe, not just functional.
.webp)
JP is a software engineer turned digital marketer based in Texas. He graduated from the University of Texas at Dallas with a degree in Software Engineering and began his career as a fullstack developer in fintech. Drawing on his technical background, JP transitioned into digital marketing freelancing, where he combines his engineering expertise with creative strategy. He brings a unique blend of technical and marketing skills to the DataAnnotation team.
Related posts



Get ahead in a changing workforce.
No recruiters. No interviews. Just meaningful work and real compensation.